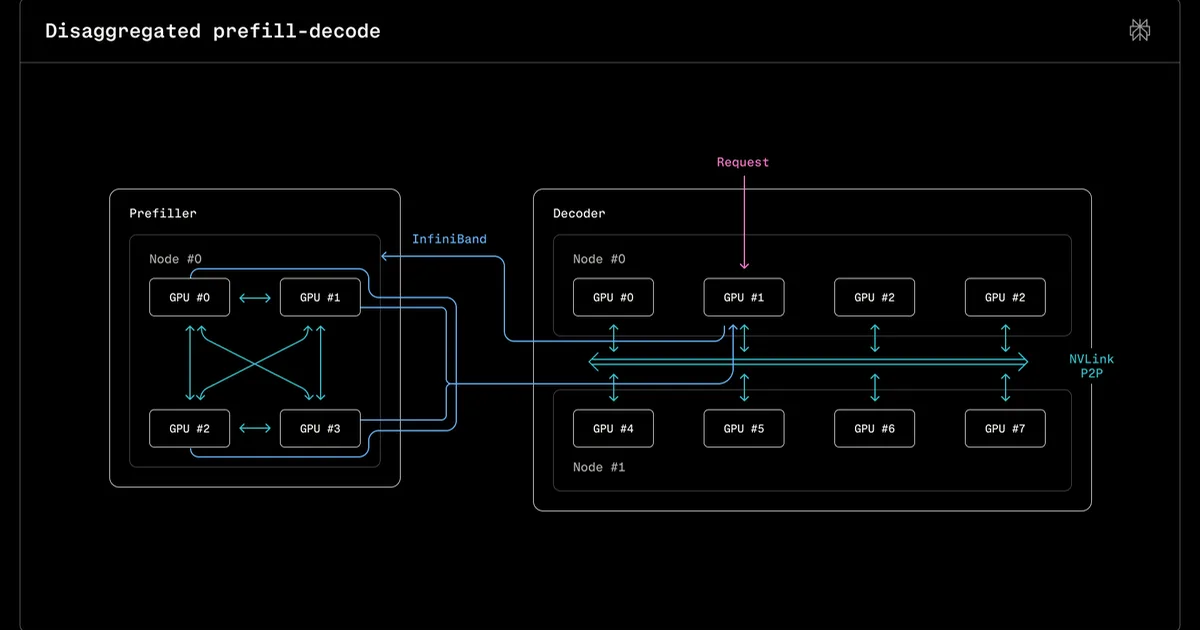
Perplexity has published research detailing how they serve large language models, specifically Qwen3 235B, on NVIDIA's GB200 NVL72 Blackwell racks. The findings indicate that the GB200 platform offers significant improvements over previous NVIDIA hardware for large-model inference, boasting reduced latency and higher throughput. This research highlights the GB200's capabilities for both training and high-throughput inference, particularly for Mixture-of-Experts (MoE) models. AI
IMPACT NVIDIA's GB200 Blackwell platform shows significant gains in LLM inference speed and cost-efficiency, potentially accelerating deployment of large models.
RANK_REASON Cluster contains research published by Perplexity on LLM inference hardware.
AI-generated summary · Google Gemini · from 4 sources. How we write summaries →