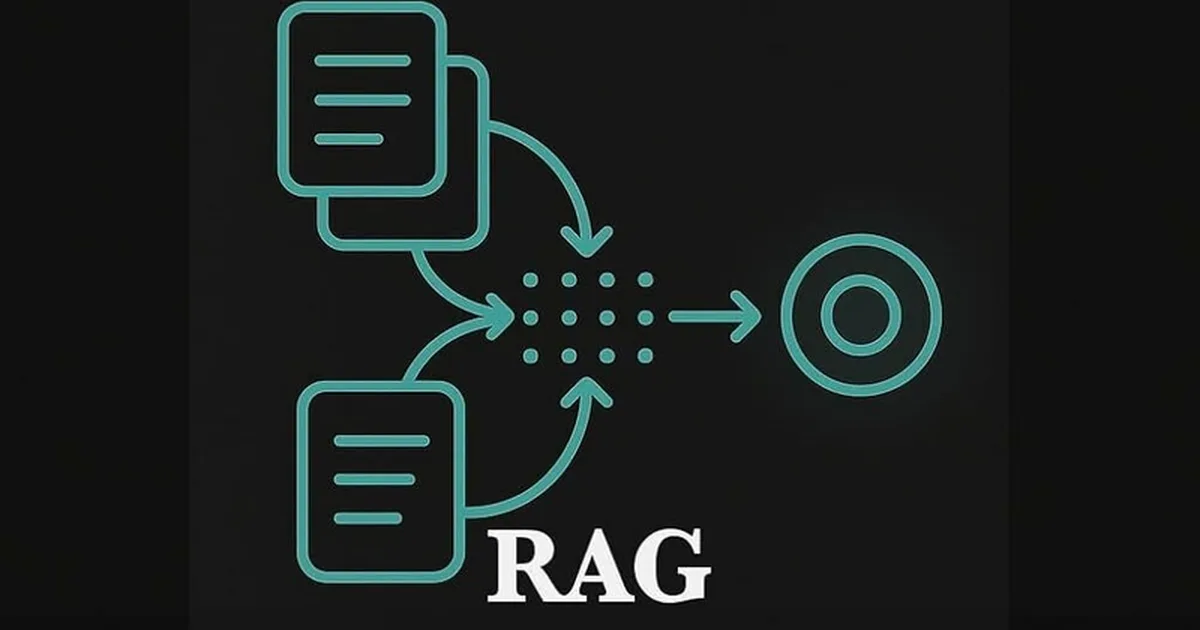
Retrieval-Augmented Generation (RAG) pipelines often fail with PDF documents due to naive text splitting methods that ignore the document's layout. This leads to corrupted chunks containing concatenated columns, misplaced footers, and detached captions, resulting in inaccurate information retrieval. The solution involves a four-layer approach: detecting the correct reading order of text blocks, classifying blocks by semantic role (e.g., text, table, figure), removing repetitive headers and footers, and chunking content by document structure (sections) rather than arbitrary token counts. This layout-aware chunking significantly improves retrieval accuracy compared to standard methods, even with the same embedding models. AI
IMPACT Improves RAG accuracy on complex documents like PDFs by addressing layout-specific challenges, leading to more reliable AI-driven information retrieval.
RANK_REASON The item discusses a technical approach to improve AI model performance on a specific data type (PDFs) by detailing a multi-layer chunking strategy, akin to a research paper or technical guide. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →