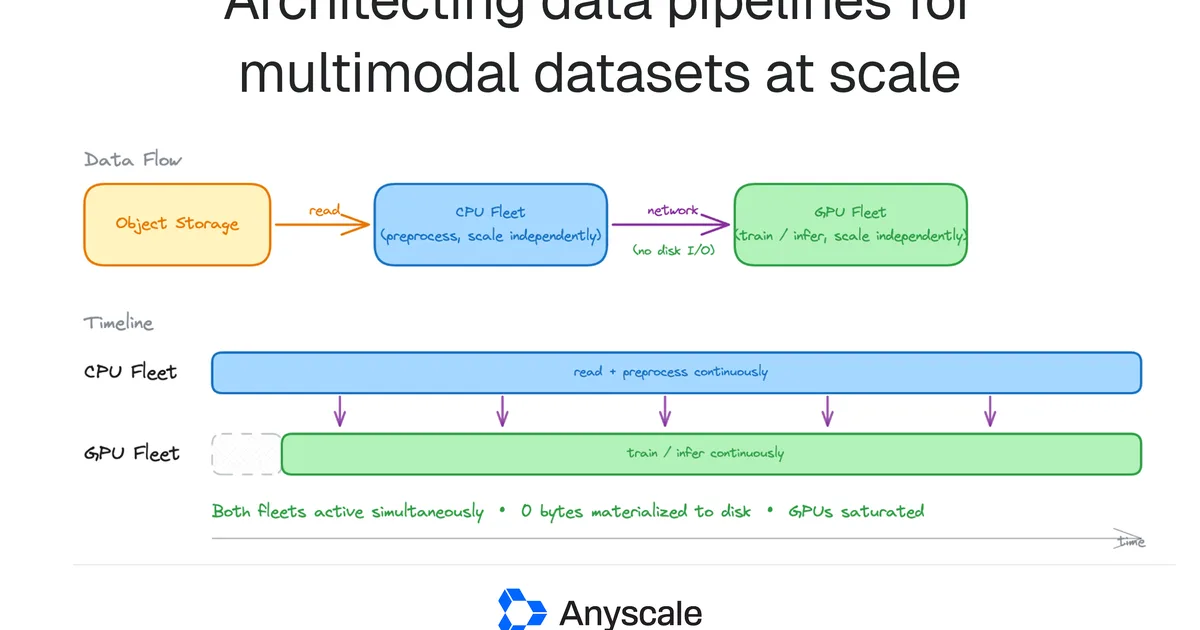
Anyscale's blog post details challenges in scaling multimodal AI data pipelines, where preprocessing often starves GPUs, leading to underutilization. The article explains that traditional staged batch execution, which involves writing intermediate data to storage between preprocessing and training, is inefficient due to significant I/O costs and delays. It proposes a disaggregated streaming architecture using Ray Data to directly stream preprocessed data from a dedicated preprocessing fleet to GPU workers, bypassing storage bottlenecks and improving GPU utilization. AI
IMPACT Provides architectural guidance for optimizing AI training and inference infrastructure, particularly for multimodal datasets.
RANK_REASON Blog post explaining technical architecture and challenges, not a product release or research breakthrough.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →