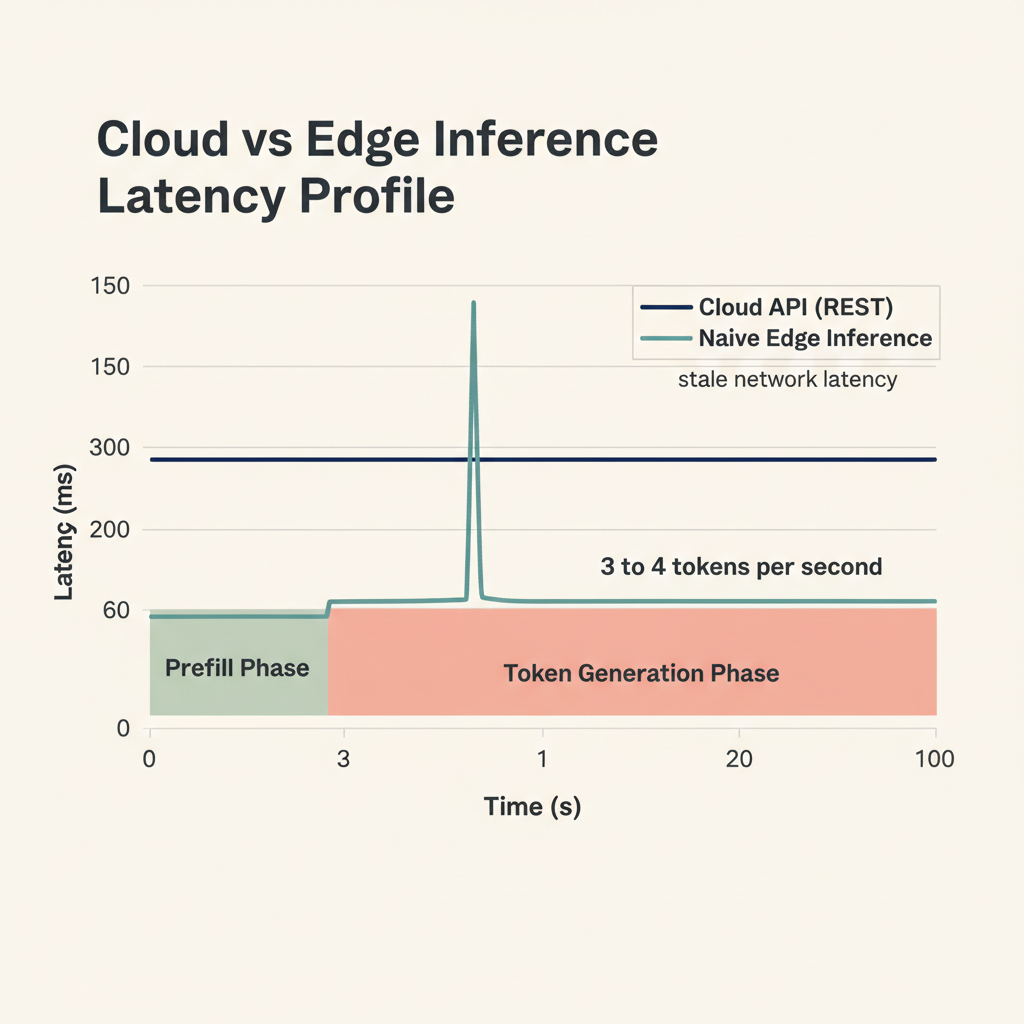
Researchers have developed a new method called LiteRT to improve the performance of edge LLMs, which are often constrained by memory bandwidth. By trading compute for bandwidth, LiteRT enables these models to achieve speeds of up to 30 tokens per second. This approach addresses a key bottleneck in deploying powerful AI models on resource-limited devices. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Enables faster and more efficient deployment of LLMs on edge devices, overcoming memory bandwidth limitations.
RANK_REASON The cluster describes a new technical method for improving LLM performance, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]