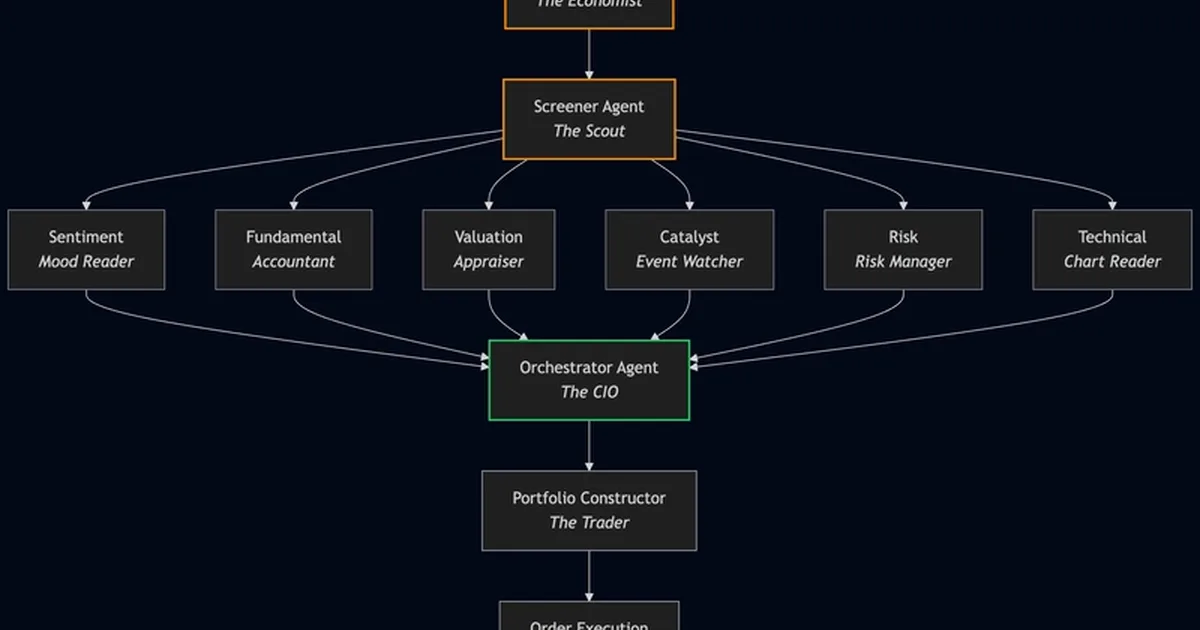
A new benchmark, dubbed 1rok, has been launched to evaluate the stock-picking capabilities of frontier large language models. The benchmark assigns each participating LLM a virtual portfolio of $100,000 and tasks them with selecting stocks weekly, with performance tracked against market outcomes. This initiative aims to provide a more practical, downstream evaluation of LLMs beyond traditional coding and reasoning benchmarks, focusing on decision-making under uncertainty. AI
IMPACT Provides a novel benchmark for evaluating LLM decision-making under uncertainty, moving beyond traditional coding and reasoning tasks.
RANK_REASON The article describes a new benchmark for evaluating LLMs on a specific downstream task (stock picking), which is a form of research and evaluation. [lever_c_demoted from research: ic=1 ai=1.0]
- 1rok
- DeepSeek V4 Pro
- Gemini 3.1 Pro Preview
- GLM-5.1
- GPT-5.5
- Grok 4.3
- Kimi K2.6
- MiniMax M2.7
- Moonshot
- OpenAI
- xAI
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →