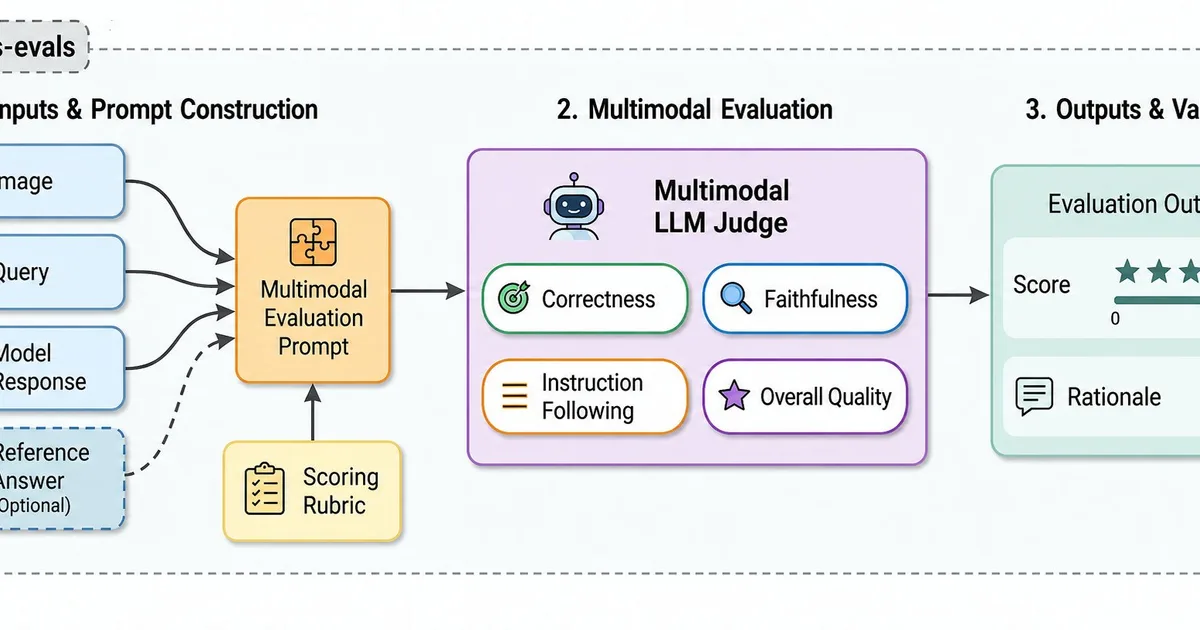
Amazon Web Services has introduced new multimodal evaluators for its Strands Evals SDK, designed to assess image-to-text tasks. These tools leverage large multimodal models (MLMMs) to judge responses by directly referencing the source image, addressing limitations of text-only evaluation methods. The evaluators can identify visual hallucinations and factual errors, integrating into existing development workflows for automated quality control. AI
IMPACT Enhances automated evaluation for multimodal AI applications, reducing reliance on manual review.
RANK_REASON Product update for an existing SDK.
Read on AWS Machine Learning Blog →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →