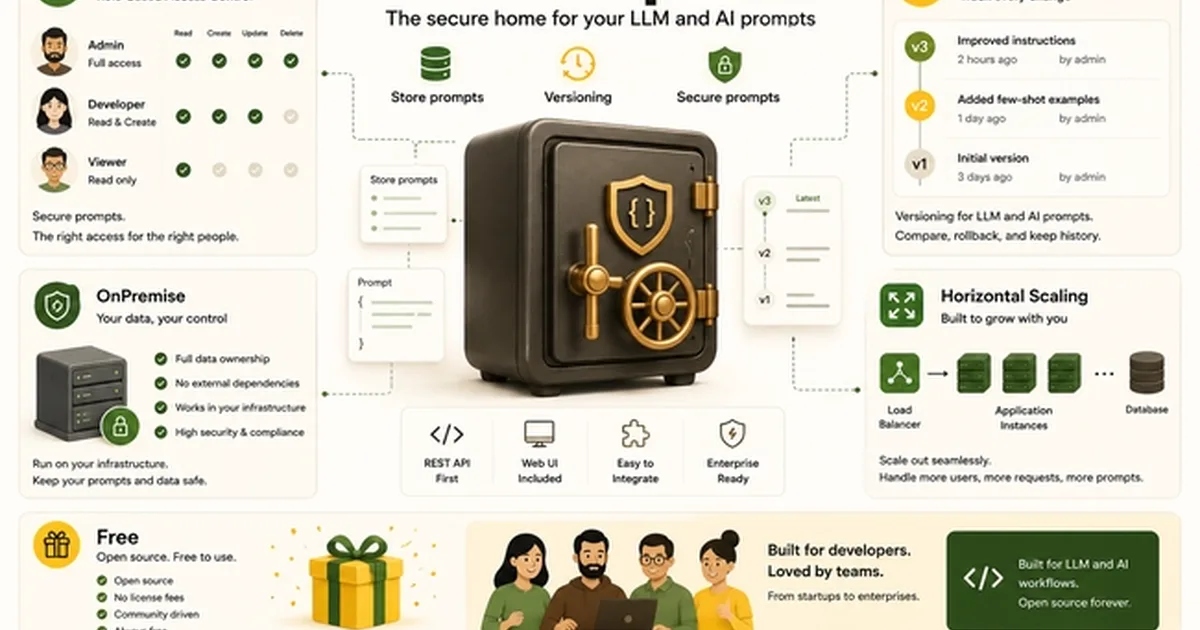
This tutorial explains how to build a custom scoring framework in Python to objectively benchmark prompt variants for large language models, moving beyond subjective evaluations. It details setting up a development environment, defining clear evaluation criteria, and using tools like the OpenAI client library and pytest. The second article discusses the challenges engineering teams face with managing and versioning prompts as application logic, highlighting PromptMan as a robust, open-source, on-premise solution with a REST API-first design for secure and scalable prompt management. AI
IMPACT Provides practical guidance for developers on systematically evaluating and managing LLM prompts, crucial for production-level AI applications.
RANK_REASON The cluster contains a tutorial on building a benchmarking framework for LLM prompts and a review of prompt management tools, which falls under research and tooling.
- Flowise
- LangSmith
- Notion
- Obsidian
- Prompt Engineering
- Promptfoo
- PromptHub
- PromptLayer
- PromptMan
- PromptPal
- PromptPerfect
- Anthropic
- OpenAI
- Python
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →