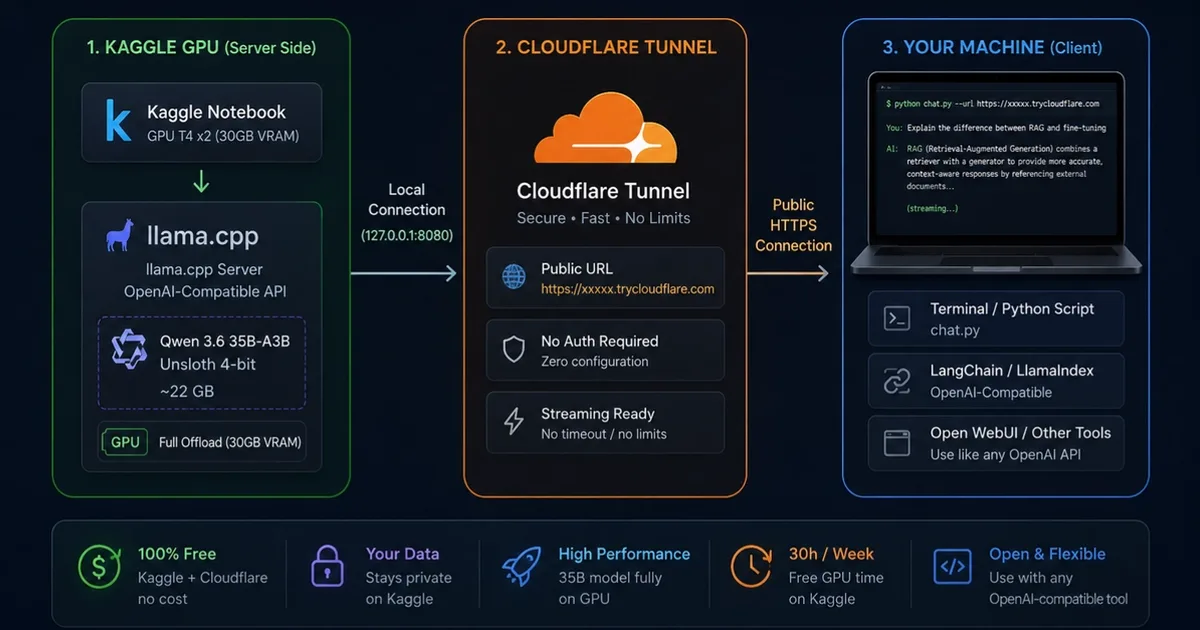
A developer has created a method to run a 35 billion parameter multimodal LLM on free Kaggle GPUs, overcoming the typical limitations of such platforms. The solution involves using Qwen3.6-35B-A3B quantized to 4-bit, hosted on Kaggle's T4 GPUs for up to 12 hours per session. It leverages llama.cpp for inference and an OpenAI-compatible API, with Cloudflare Quick Tunnel providing a stable public URL that supports token streaming, unlike other free tunneling services. AI
IMPACT Enables developers to run powerful LLMs on free cloud GPUs, bypassing costly hardware or API fees.
RANK_REASON The cluster describes a technical setup and guide for running an existing open-source LLM on a free platform, rather than a new model release or significant industry event.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →