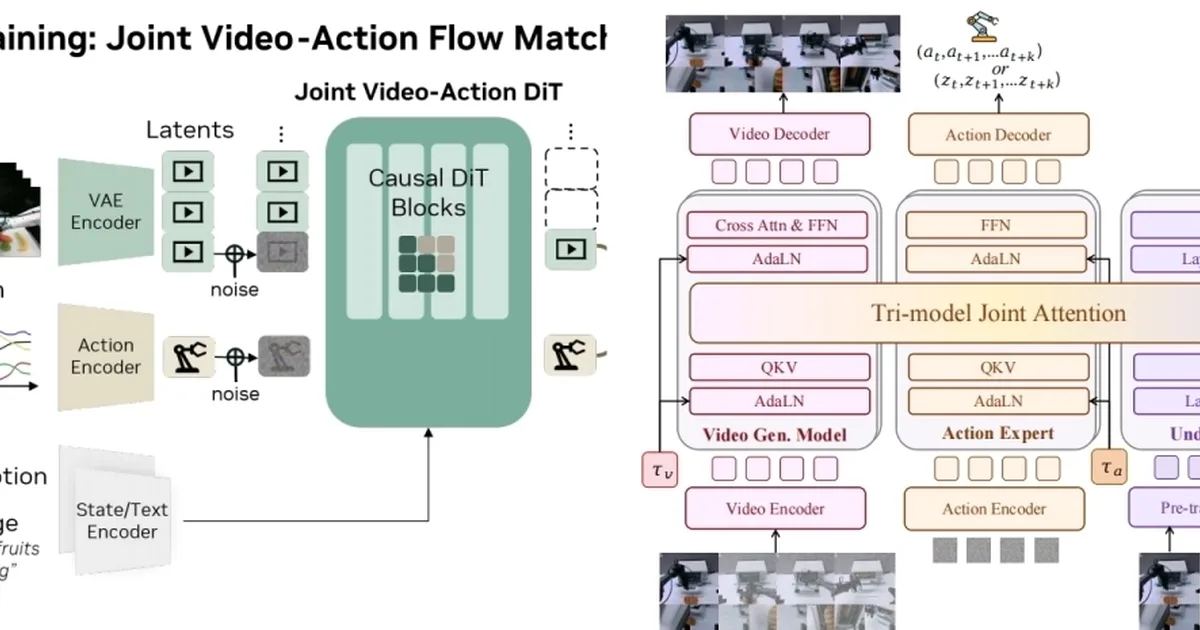
DreamZero and Motus represent distinct approaches to World Action Models (WAMs), both utilizing flow matching and chunk-based generation for video and action sequences. DreamZero employs an autoregressive, causal generation method, processing data chronologically and adhering to causal attention masking, making it suitable for real-time robotic control. In contrast, Motus offers a flexible, unified framework based on a bidirectional, non-causal architecture, capable of generating entire future video and action chunks simultaneously and supporting multiple task modes. AI
IMPACT Details novel generation paradigms for World Action Models, impacting robotics and video-action sequence generation research.
RANK_REASON The cluster describes two distinct research approaches to World Action Models, detailing their architectural and methodological differences. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →