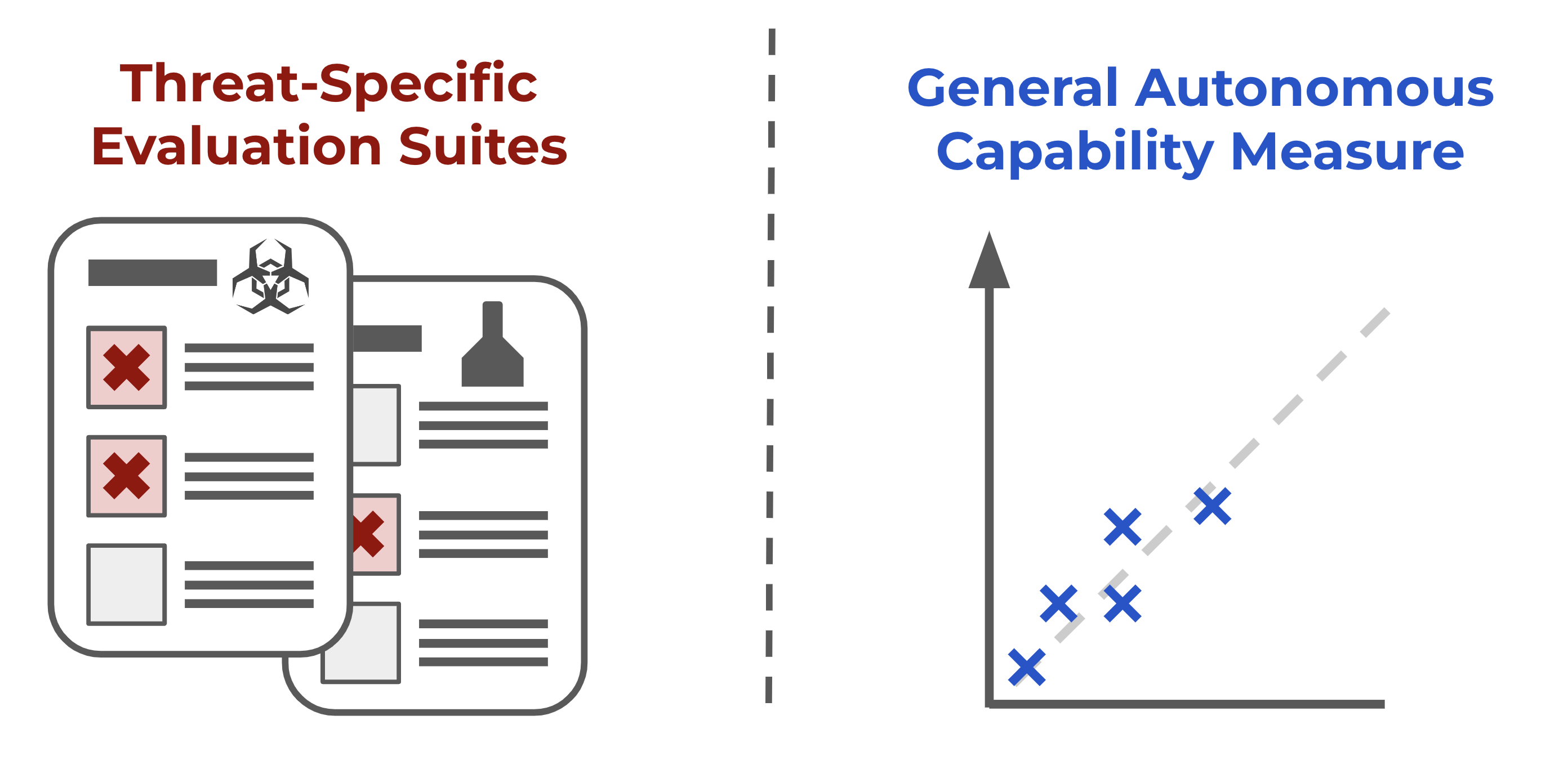
METR has developed a new suite of approximately 50 automatically scored tasks designed to measure general autonomous capabilities in AI systems. These tasks span various skills including cybersecurity, software engineering, and machine learning, with preliminary evaluations showing that agents based on models like GPT-4o and Claude can complete a fraction of these tasks comparable to human performance within a short timeframe. The evaluation suite aims to provide a continuous measure of AI autonomy, serving as a proxy for an AI's potential global impact and aiding in capability forecasting. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The cluster describes the development and preliminary results of a new AI evaluation task suite from METR, which is an academic/research-oriented organization.