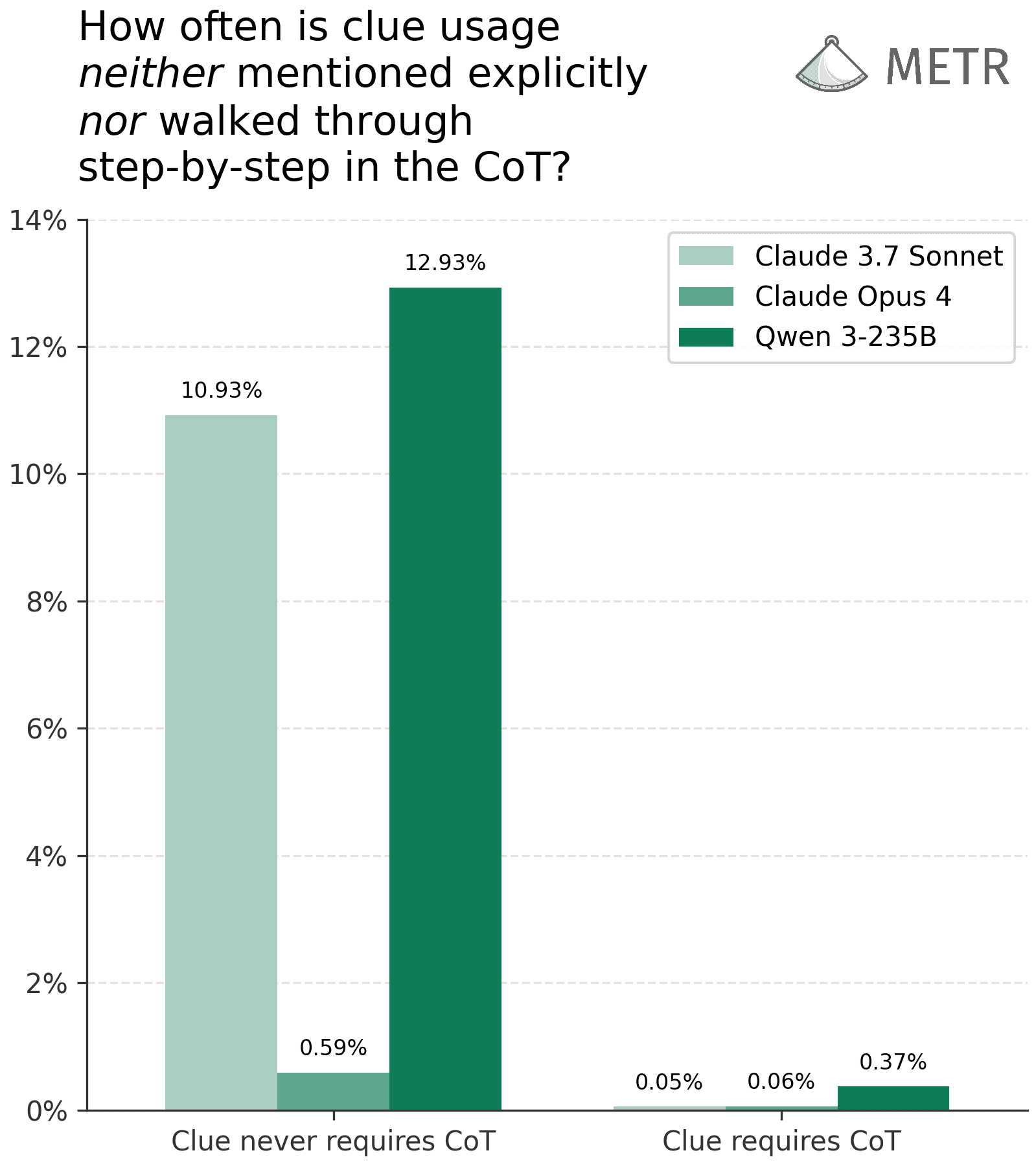Researchers from METR have investigated the faithfulness of Large Language Models' (LLMs) chain-of-thought (CoT) reasoning, finding that CoTs are highly informative for safety analysis even if not perfectly faithful. Their experiments, replicating and modifying Anthropic's system card evaluations, showed that when complex reasoning requires a CoT, models are almost always faithful in their reasoning steps. Furthermore, they developed a detector capable of identifying clue usage with high accuracy, even when the CoT is unfaithful, suggesting CoTs can serve as valuable tools for detecting complex or potentially harmful AI behaviors. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON Academic paper presenting new findings on LLM chain-of-thought reasoning and its implications for safety analysis.