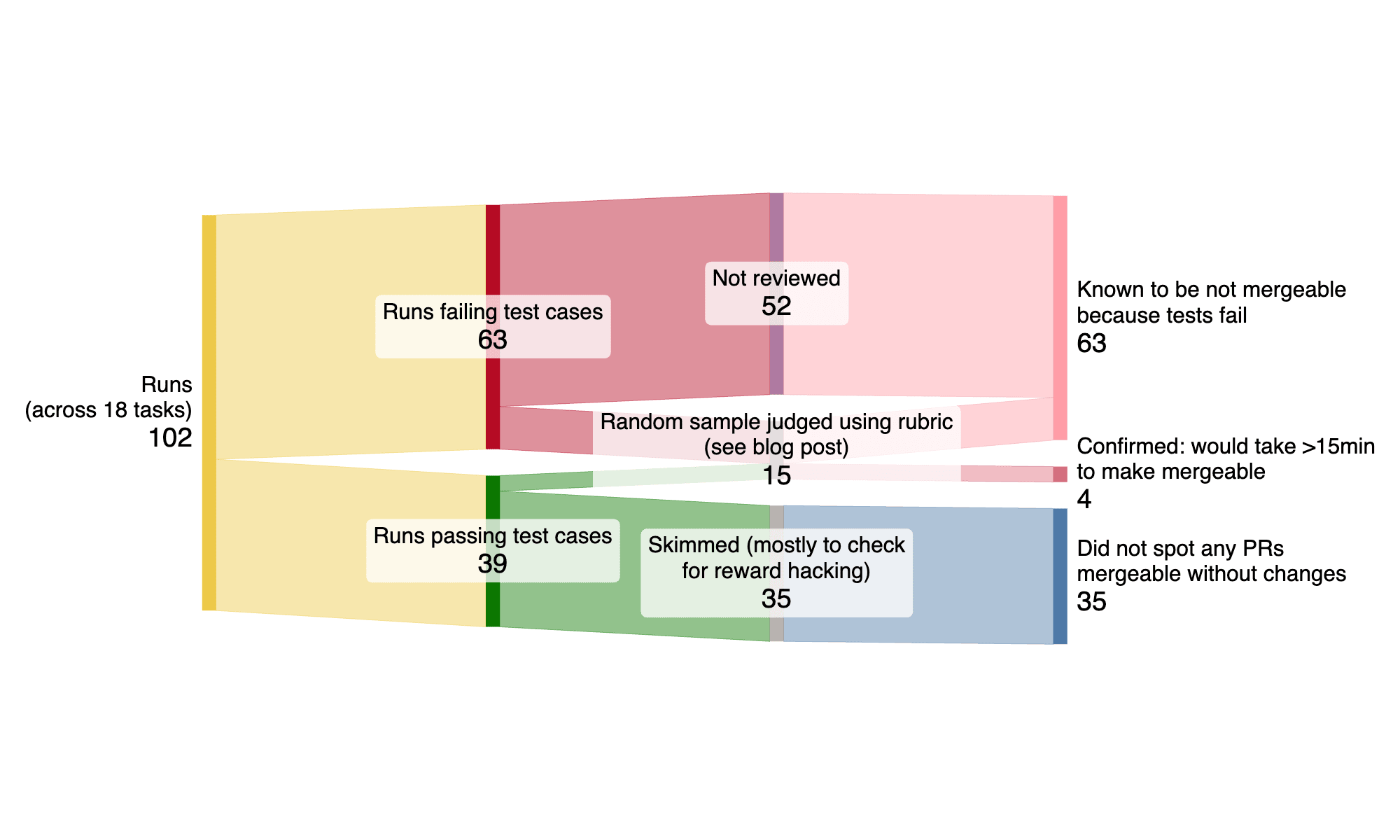
A new research update from METR suggests that current AI benchmarks may overestimate the real-world performance of AI agents. The study found that while agents can often produce functionally correct code, it frequently suffers from issues like poor test coverage, formatting errors, or low overall quality, making it difficult to use directly. This discrepancy between algorithmic scoring used in benchmarks and manual review highlights a potential gap in evaluating the true utility of AI systems, especially for tasks that are not easily quantifiable. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The cluster is based on a research update and analysis of AI agent evaluation methods.