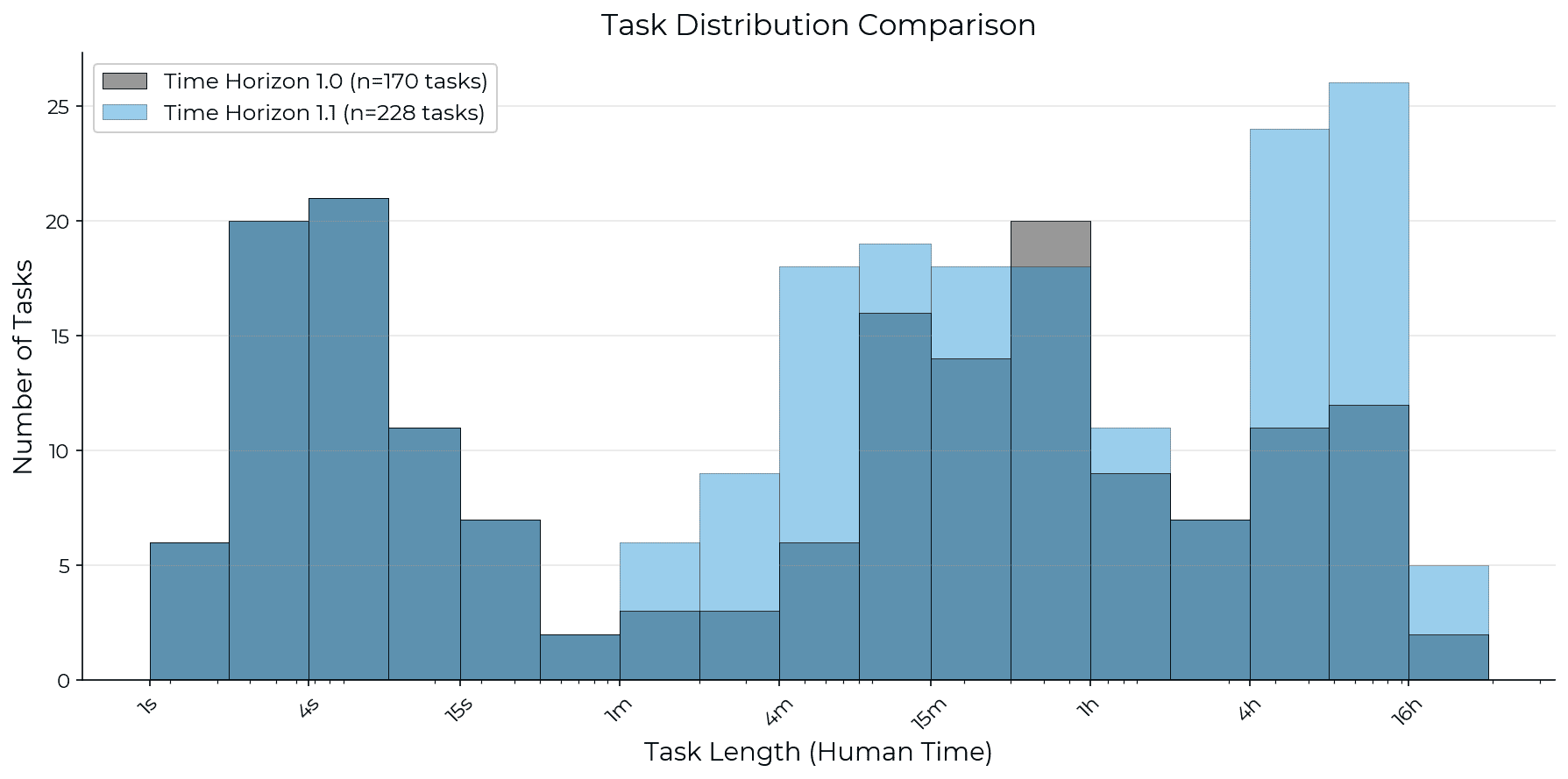
METR has released Time Horizon 1.1, an updated methodology for evaluating AI model capabilities. This new version expands the task suite by 34% and increases the number of long-duration tasks, aiming for tighter confidence intervals in capability estimates. The evaluation infrastructure has also been migrated to the open-source Inspect framework. While most new estimates fall within previous confidence intervals, the overall trend in AI model advancement appears slightly altered. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON This is a research update on an evaluation methodology for AI models, not a new model release or significant policy change.