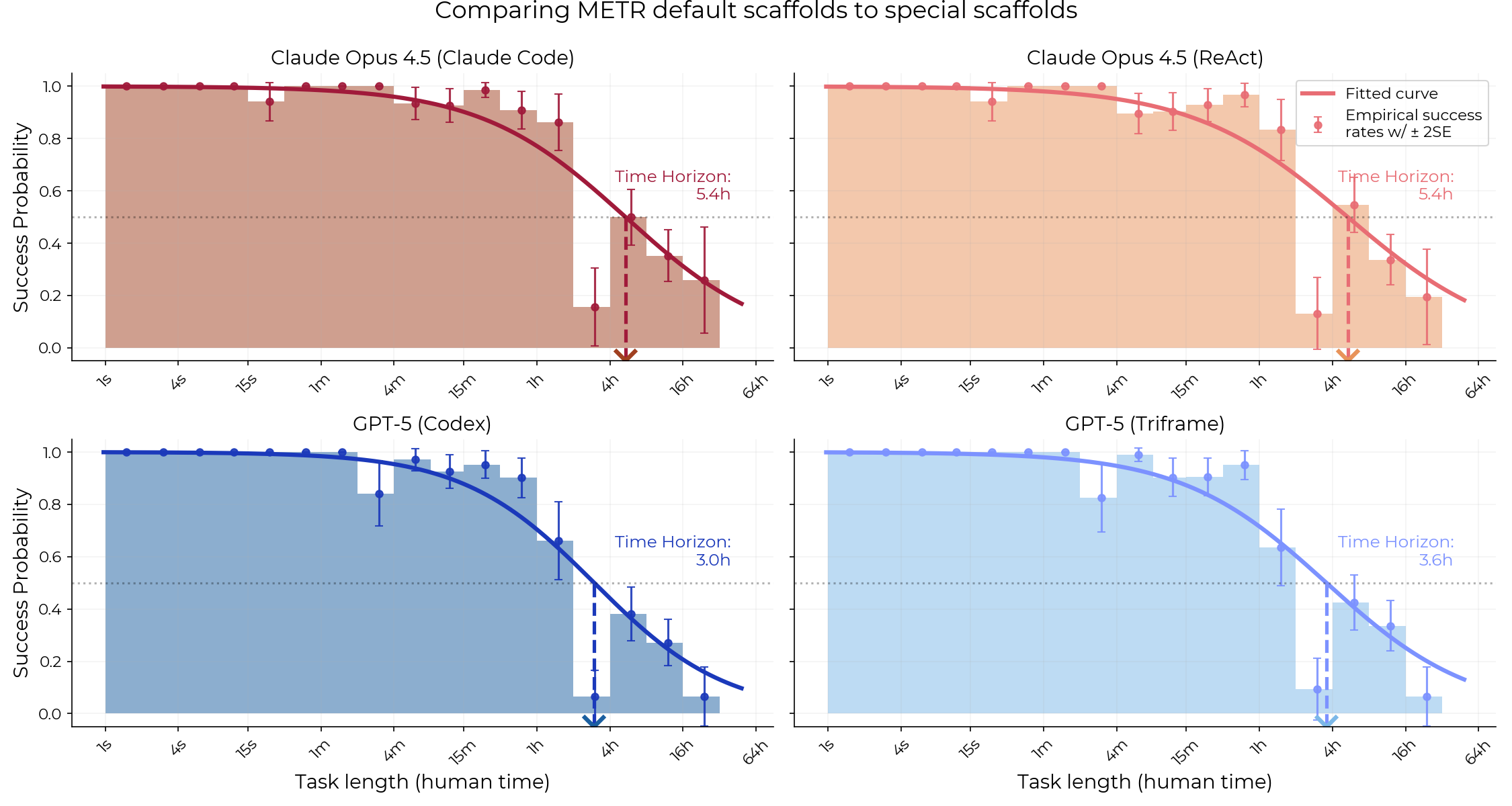
A recent evaluation by METR (Model Evaluation & Threat Research) found that specialized scaffolds like Claude Code and Codex do not significantly outperform their general-purpose scaffolds (Triframe and ReAct) when measuring the time horizon capabilities of models like Opus 4.5 and GPT-5. Despite being optimized for software engineering tasks and prompted more elaborately, these specialized scaffolds showed no statistically significant advantage. The research involved comparing model performance on METR's existing task suite using both the general and specialized scaffolds, with minor adjustments made to the specialized agents for evaluation. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The cluster is based on a research paper evaluating AI model capabilities using specific methodologies.