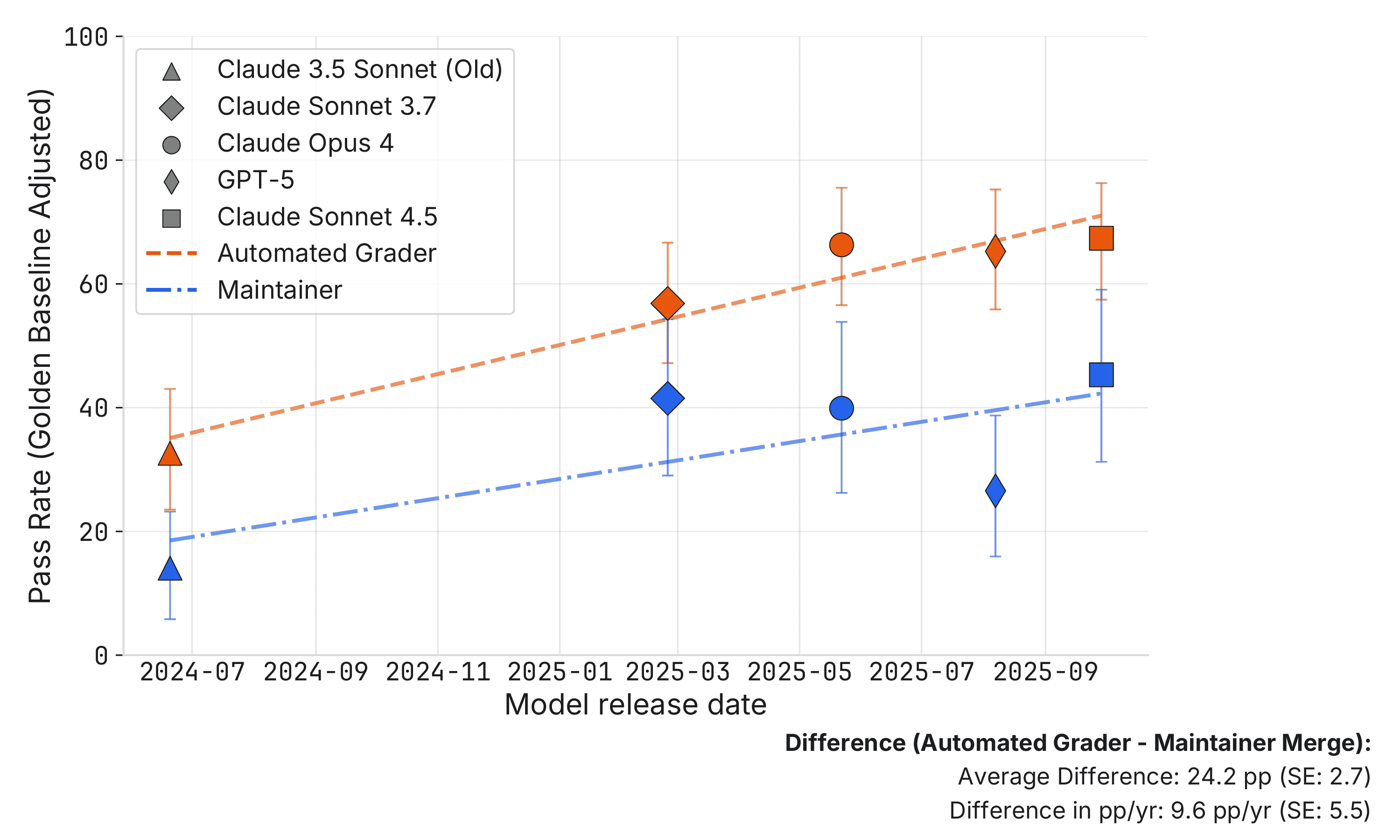
A new study from METR reveals that approximately half of the pull requests (PRs) generated by AI agents that pass automated SWE-bench tests would not be accepted by human maintainers. This discrepancy suggests that current benchmark scores may overestimate the real-world usefulness of AI code generation tools. The research highlights that AI agents lack the iterative feedback loop that human developers benefit from, and a naive interpretation of benchmark results could lead to inflated expectations of AI capabilities. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The cluster is based on an academic paper evaluating AI model performance on a software engineering benchmark.