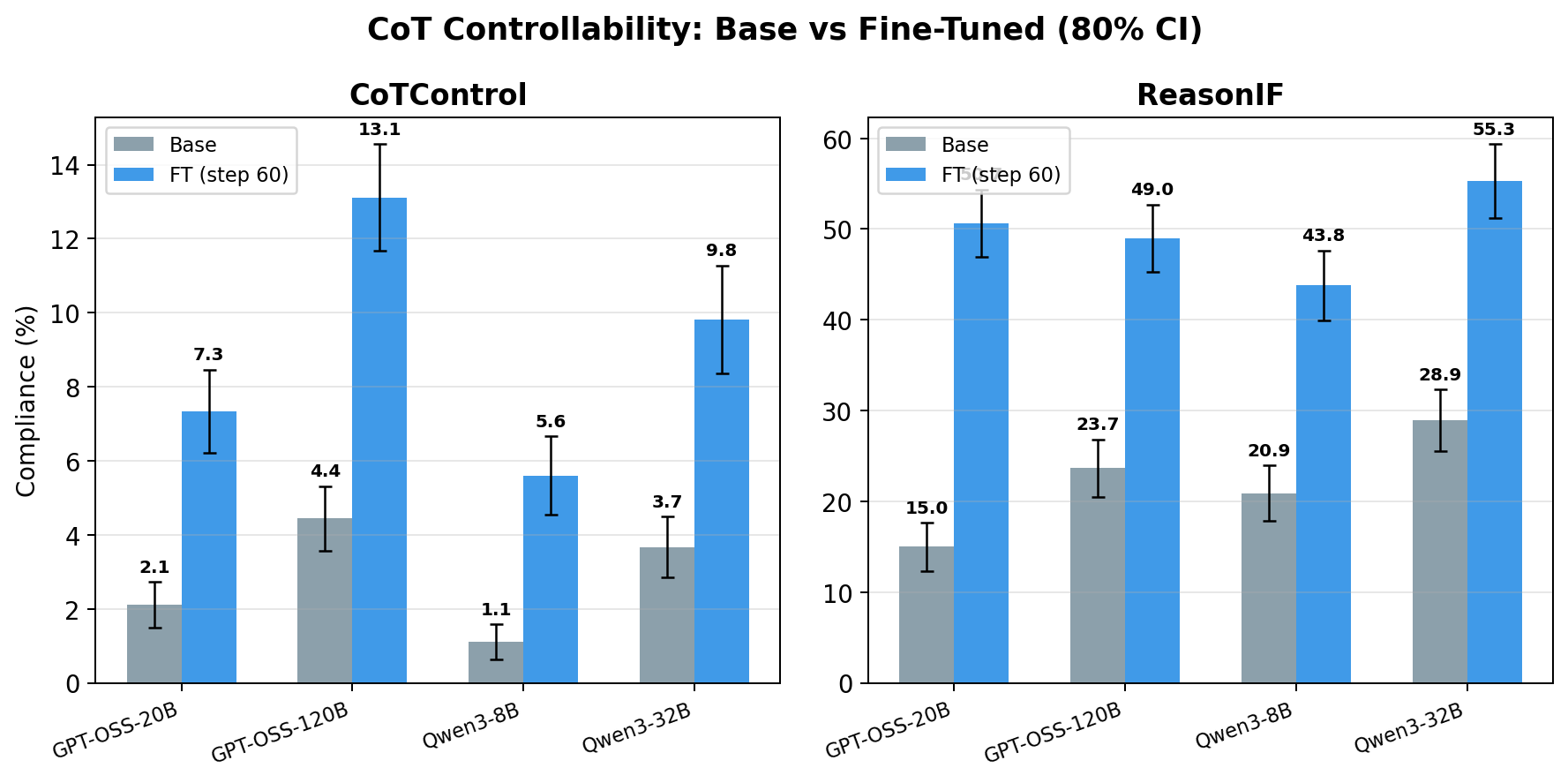
Researchers have found that fine-tuning reasoning models on a small dataset of instruction-following examples can significantly improve their ability to control their Chain-of-Thought (CoT) reasoning traces. This improvement, observed across four different models, led to an increase in CoT controllability from an average of 2.9% to 8.8% on out-of-distribution tasks. The study suggests that even minimal fine-tuning can elicit latent controllability capabilities, indicating that poor CoT controllability in current models might not be a robust limitation. However, the researchers note that frontier AI labs may not prioritize such fine-tuning, and the implications for multi-turn or agentic settings remain unclear. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The cluster reports on an academic paper detailing fine-tuning experiments on reasoning models to improve CoT controllability.