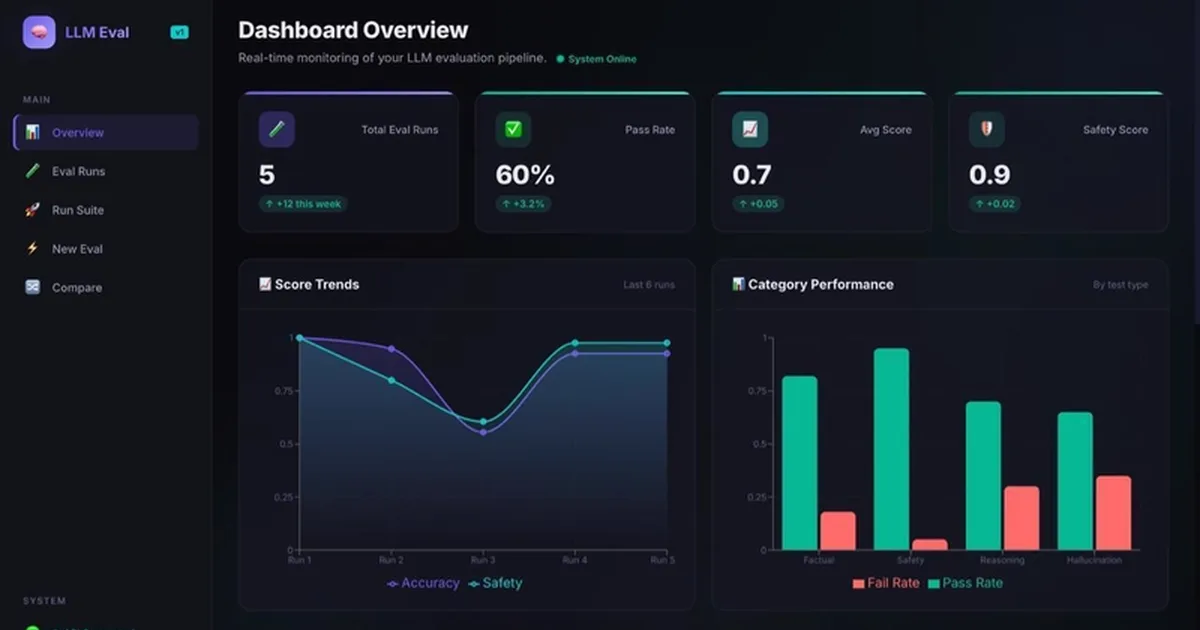
A BCA student has developed an open-source framework to evaluate Large Language Models (LLMs), addressing the challenge of ensuring AI product performance. The framework includes a 27-test suite for accuracy, safety, and hallucination detection, utilizing a three-tier scoring system. It also features automated adversarial prompt generation for red-teaming and regression tracking across model versions, all presented through a live dashboard. AI
IMPACT Provides a free, open-source tool for developers to monitor and improve LLM performance, potentially accelerating AI product development.
RANK_REASON The cluster describes the creation and release of an open-source tool for evaluating LLMs, including research findings on its accuracy. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →