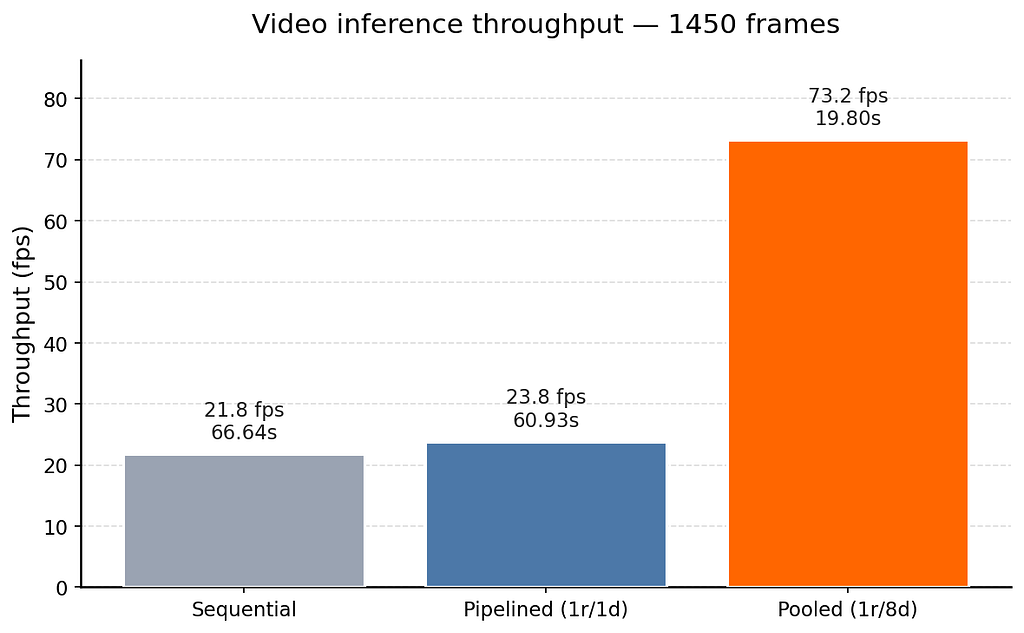
Researchers have developed a method to significantly accelerate video inference for computer vision models without altering the model itself. By optimizing the pipeline of frame reading, model inference, and result visualization, they achieved a threefold speed increase. This approach leverages multi-threading to parallelize tasks like frame decoding, inference, and image writing, ensuring the GPU is utilized more effectively. The optimized method aims to make inference speed less dependent on the slowest component, such as frame decoding or image saving. AI
IMPACT Optimizing inference pipelines can reduce latency and computational costs for real-time AI applications like video analysis.
RANK_REASON The cluster describes a novel method for optimizing AI model inference speed through pipeline engineering, rather than model architecture changes. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →