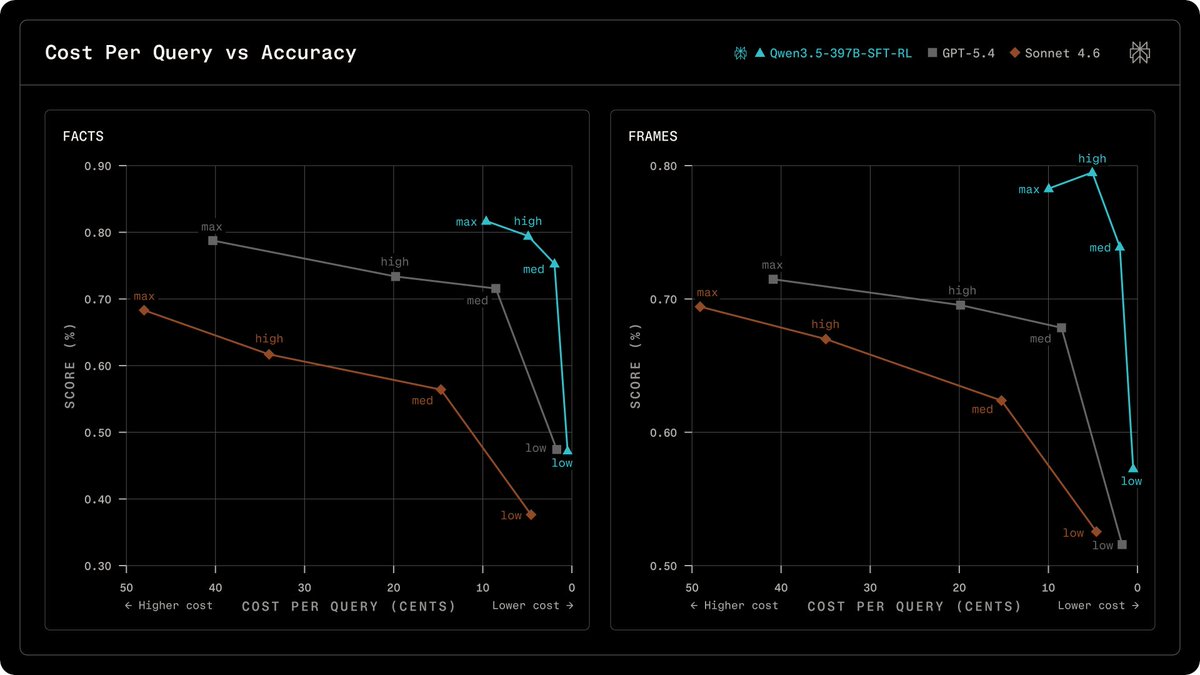
Perplexity has detailed its proprietary post-training pipeline that enhances base models for search-augmented question answering. This process involves initial fine-tuning for instruction following and safety, followed by on-policy reinforcement learning to boost search accuracy and efficiency. The company's reward design prioritizes correctness and user preference, preventing the model from generating plausible but incorrect responses. Perplexity claims this method, when applied to Alibaba's Qwen models, achieves comparable or superior factuality to GPT models at a reduced cost. AI
Summary written by gemini-2.5-flash-lite from 5 sources. How we write summaries →
IMPACT Perplexity's research details a pipeline that improves model accuracy and efficiency for search-augmented answers, potentially lowering operational costs.
RANK_REASON Perplexity published new research detailing their model post-training pipeline.