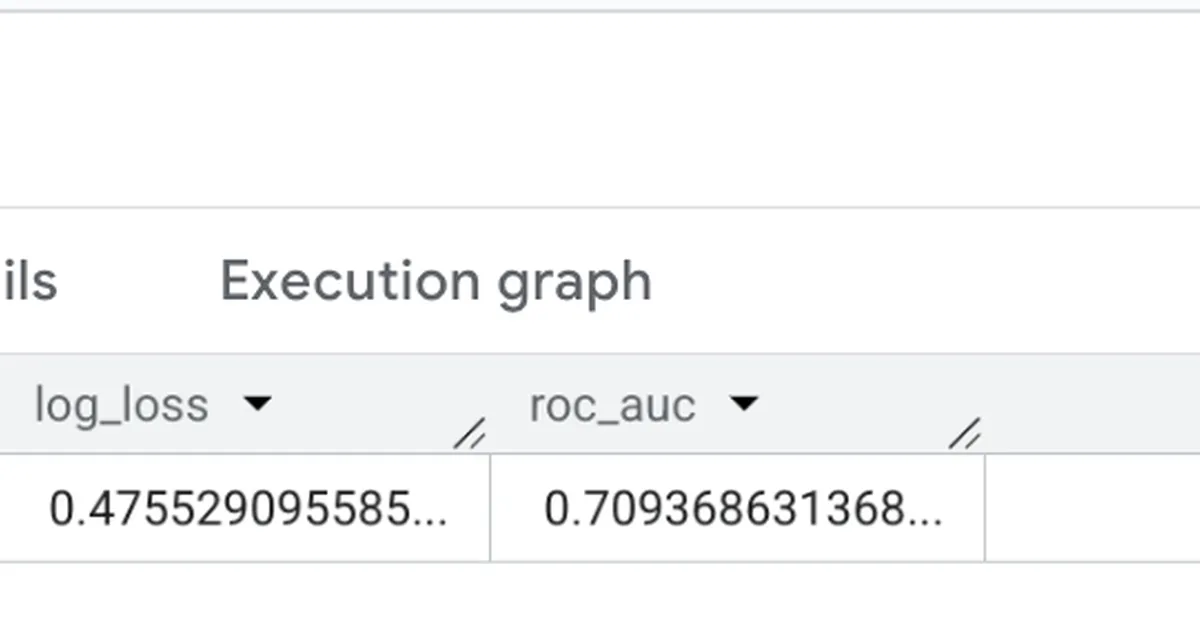
The author recounts an experience where their credit risk model, trained using BigQuery ML, initially appeared to be underperforming with an AUC score of 0.71. Despite this score being statistically significant, the author's intuition suggested the model was flawed. This led to a period of debugging and re-evaluation to understand the discrepancy between the model's performance metrics and the expected outcome. AI
IMPACT Offers a personal anecdote about model evaluation challenges, providing limited direct impact for AI operators.
RANK_REASON The article is a personal reflection on a specific modeling experience, not a general industry trend or new release.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →