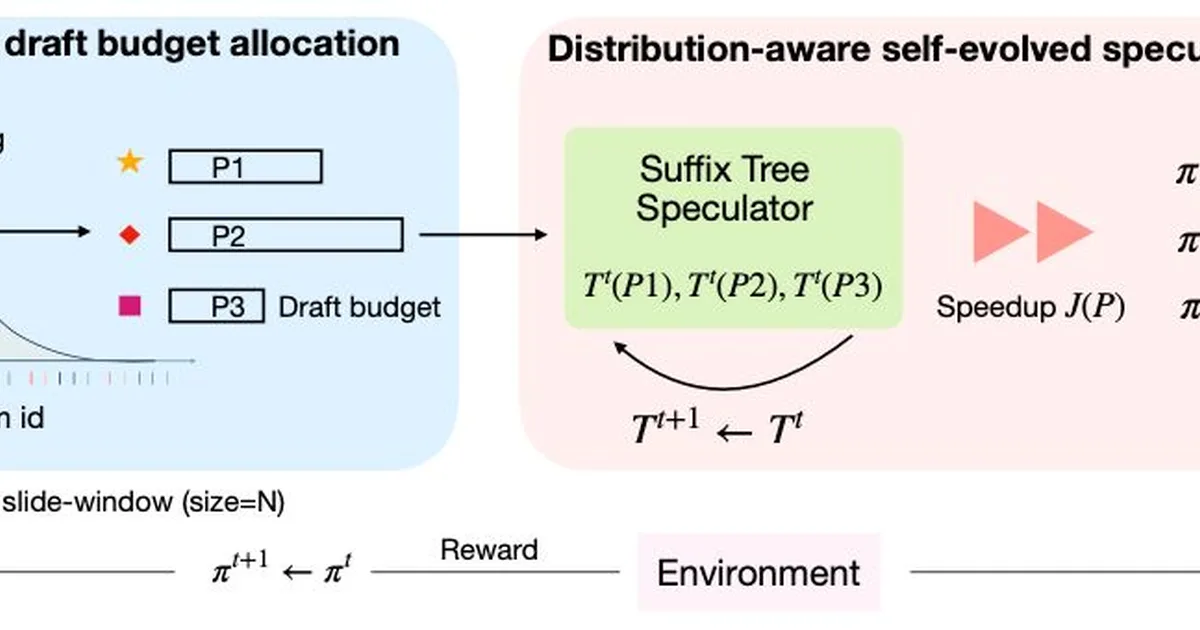
SemiAnalysis is highlighting production system challenges for large-scale AI models, particularly Mixture-of-Experts (MoE) architectures. They note that techniques like expert balancing and assigning dedicated resources to different workloads are moving from academic research into practical applications. Sparse attention mechanisms, previously confined to benchmarks, are now being implemented in production systems, with examples like DeepSeek Sparse Attention and NousResearch's work being cited. AI
IMPACT Highlights emerging production optimizations for large AI models, indicating a shift from research to practical deployment.
RANK_REASON The cluster consists of tweets discussing production challenges and techniques for AI models, rather than a specific release or event.
- DeepSeek Sparse Attention
- haoailab
- Mixture-of-Experts (MoE) models
- MLSys 2026
- NousResearch
- RL training
- SemiAnalysis
- sparse attention mechanisms
- StepFun_ai
AI-generated summary · Google Gemini · from 5 sources. How we write summaries →