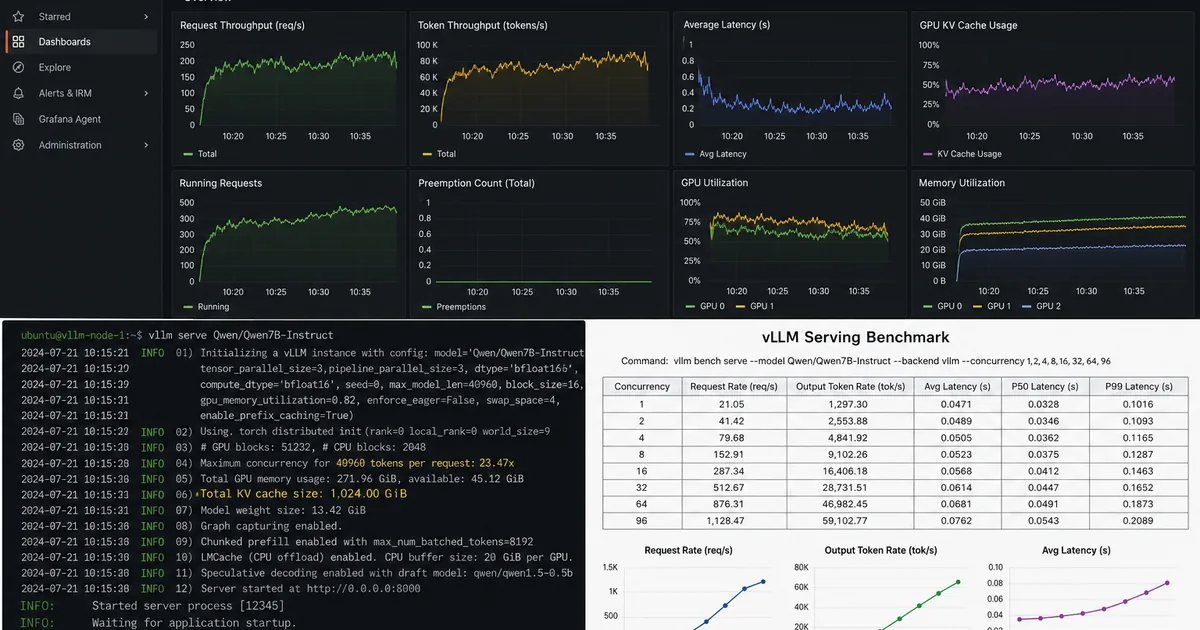
A developer detailed their process for optimizing vLLM to handle high concurrency in a production voice AI system. The setup utilized a three-node GPU cluster featuring NVIDIA A4500 and A100 cards to serve a Qwen-based model. This optimization aimed to improve the efficiency and throughput of the AI service. AI
IMPACT Provides specific technical insights for AI operators managing high-throughput inference workloads.
RANK_REASON Article describes a specific technical optimization for an existing tool (vLLM) in a production setting, rather than a new release or major industry event.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →