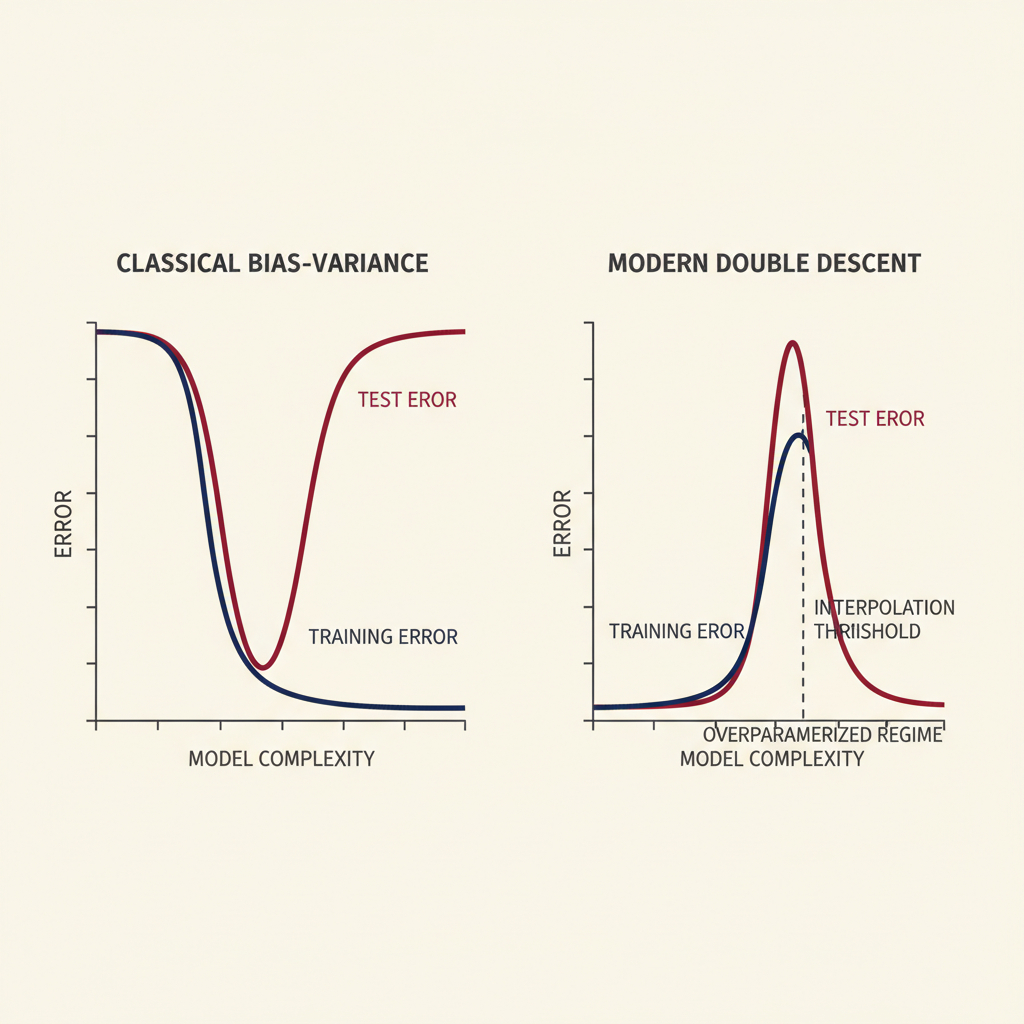
A new paper explores the limitations of the bias-variance tradeoff in large transformer models, specifically those with 70 billion parameters. The research suggests that standard Stochastic Gradient Descent (SGD) methods struggle to find "flat minima" in these complex models. This difficulty implies that traditional approaches to model optimization may not be sufficient for achieving optimal performance in state-of-the-art large language models. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Challenges conventional optimization assumptions for large models, potentially guiding future research into more effective training techniques.
RANK_REASON The cluster contains an academic paper discussing theoretical limitations of optimization methods for large transformer models. [lever_c_demoted from research: ic=1 ai=1.0]