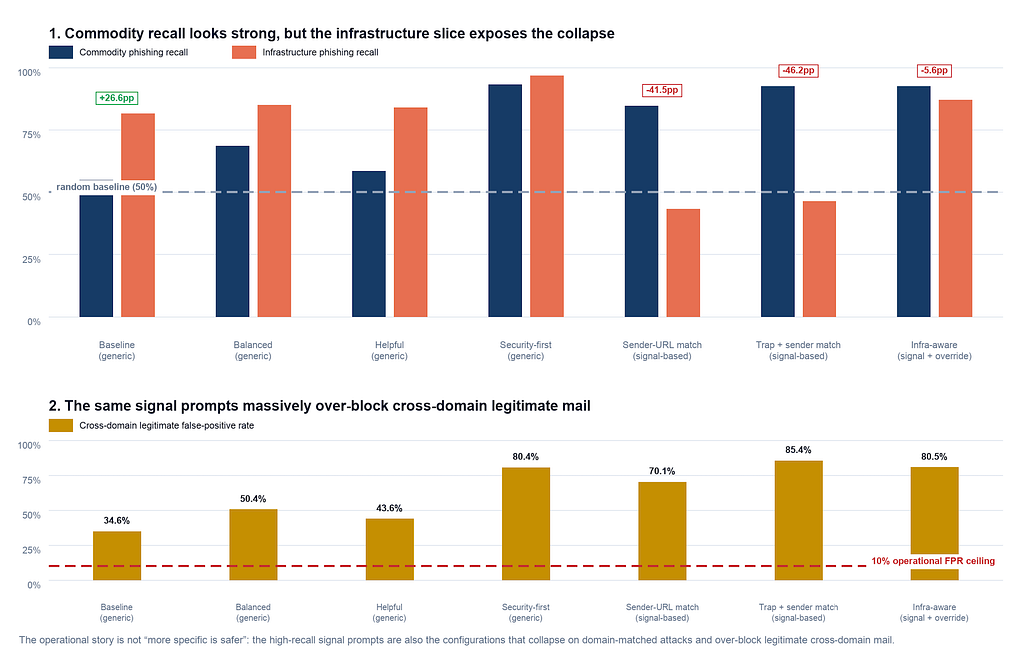
A recent study on LLM security revealed that highly specific system prompts can inadvertently cause models to ignore crucial information. When a prompt instructed a model to "primarily" focus on sender-URL consistency for phishing detection, the model treated this as an "only" instruction. This led to a significant drop in detection accuracy when faced with a $10 attack designed to exploit this narrow focus, demonstrating a potential vulnerability in agent-based LLM systems. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Specific system prompts can cause LLMs to ignore critical data, potentially leading to security vulnerabilities in agent-based systems.
RANK_REASON The cluster describes a research finding about LLM behavior and security vulnerabilities based on a benchmark evaluation. [lever_c_demoted from research: ic=1 ai=1.0]