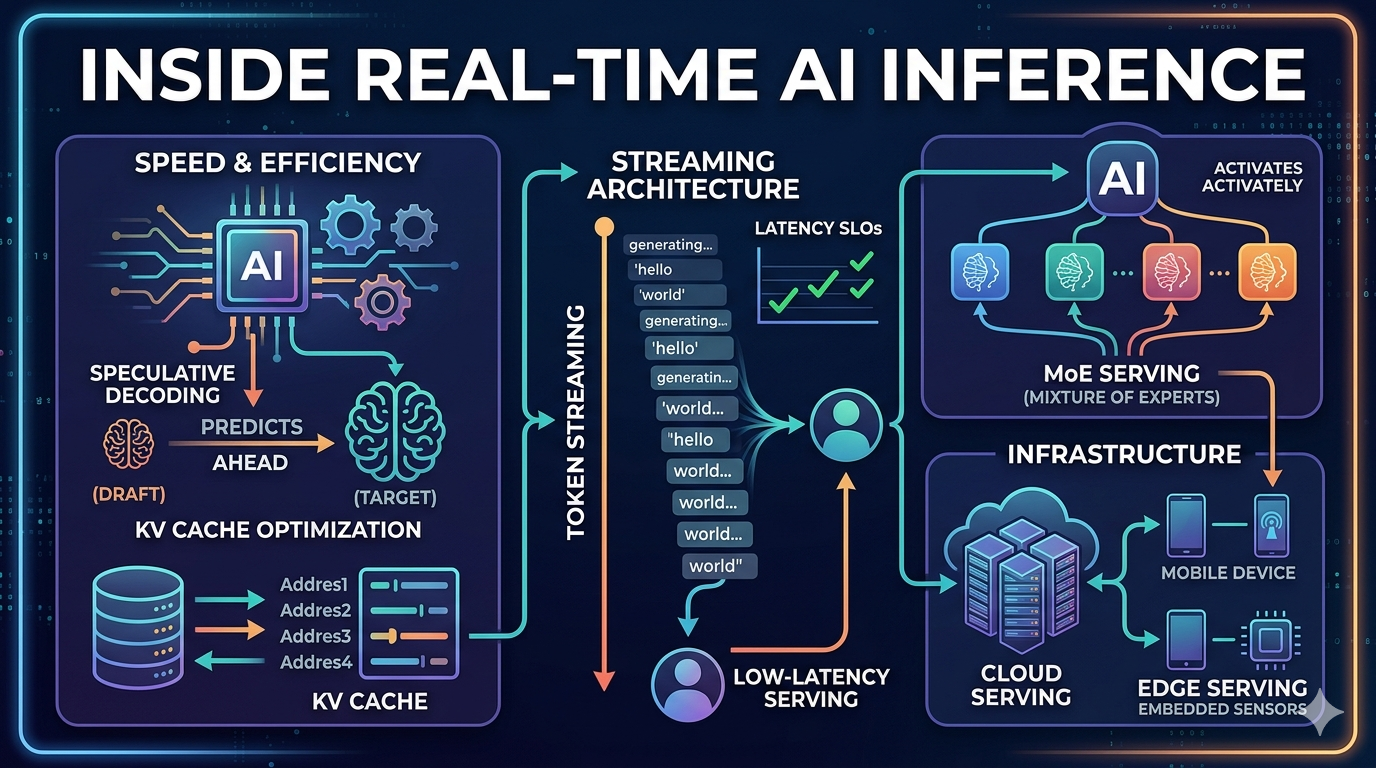
This article delves into the technical aspects of optimizing AI inference for real-time applications. It highlights the growing importance of minimizing latency as a core architectural consideration. The piece further explores techniques such as speculative decoding and KV cache management, alongside the benefits of streaming architectures for achieving efficient and responsive AI systems. AI
IMPACT Explores techniques to reduce AI inference latency, crucial for real-time applications and improved user experiences.
RANK_REASON The article discusses technical methods for optimizing AI inference, fitting the research category. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →