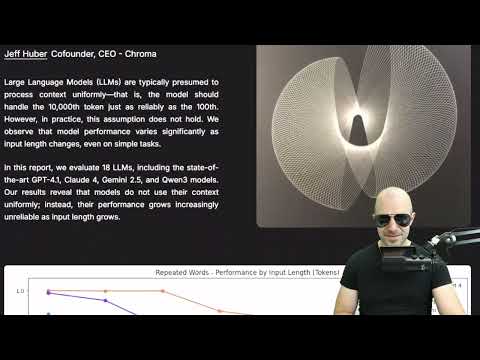
A new paper analyzing 18 large language models, including top performers like GPT-4.1, Claude 4, and Gemini 2.5, reveals a phenomenon termed 'context rot.' This occurs because LLMs do not process input tokens uniformly; their performance degrades significantly as the length of the input increases, contrary to the assumption of uniform context processing. The research indicates that models become increasingly unreliable with longer inputs, even on straightforward tasks. AI
Summary written by None from 1 source. How we write summaries →
RANK_REASON The cluster is based on an academic paper analyzing the performance of multiple LLMs.