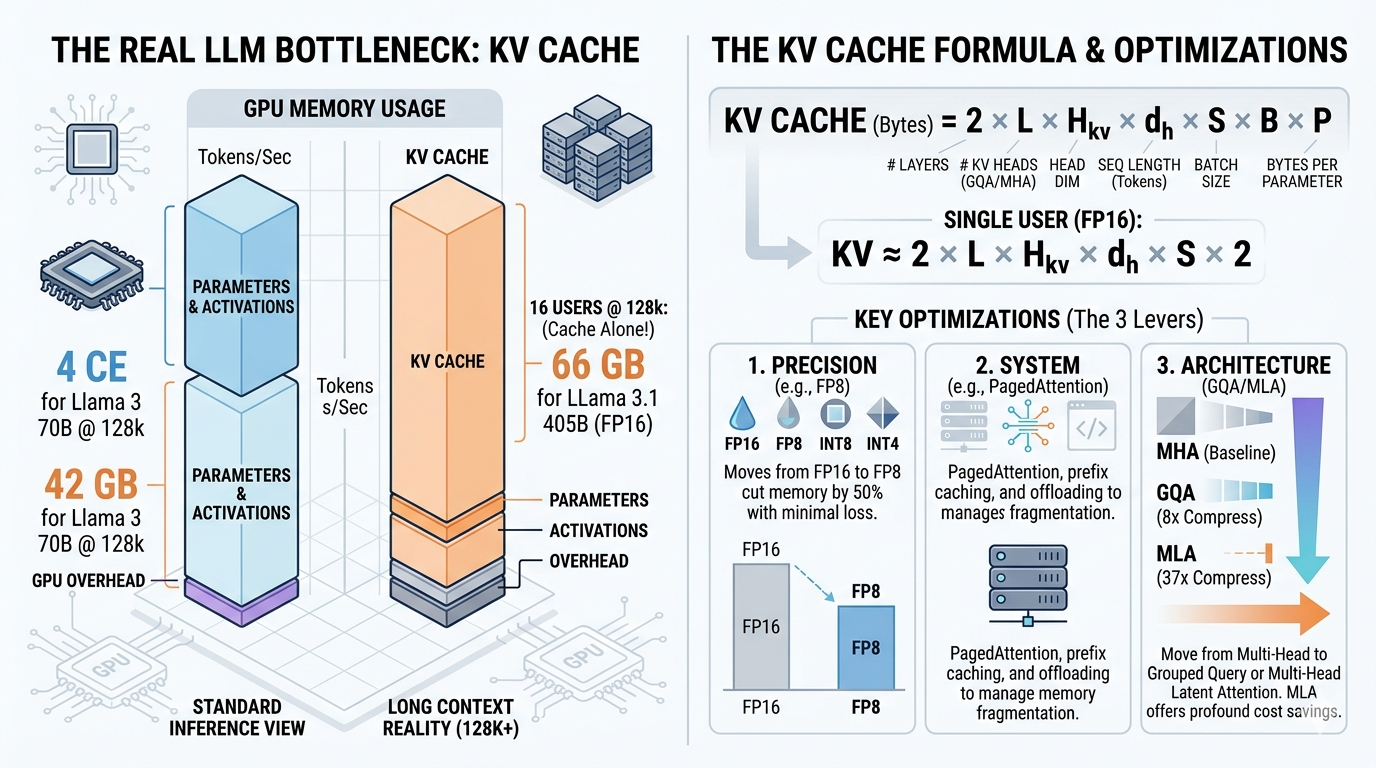
Large language models utilize KV caching to accelerate inference by storing previously computed key and value vectors, rather than recomputing them for each new token. This technique significantly speeds up token generation after an initial, more compute-intensive "prefill" phase where the cache is built. However, KV caching trades increased memory usage for reduced computation, with the cache size growing linearly with context length and potentially exceeding model weights at scale. AI
IMPACT Explains a core LLM inference optimization, impacting model efficiency and deployment costs for operators.
RANK_REASON The cluster explains a technical concept (KV caching) in LLMs, detailing its mechanics and trade-offs, which is characteristic of research or technical documentation.
- ChatGPT
- Claude
- grouped-query attention
- KV caching
- LLMs
- multi-query attention
- Paged attention
- Qwen 2.5 72B
- Transformer
- Llama 3.1 405B
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →