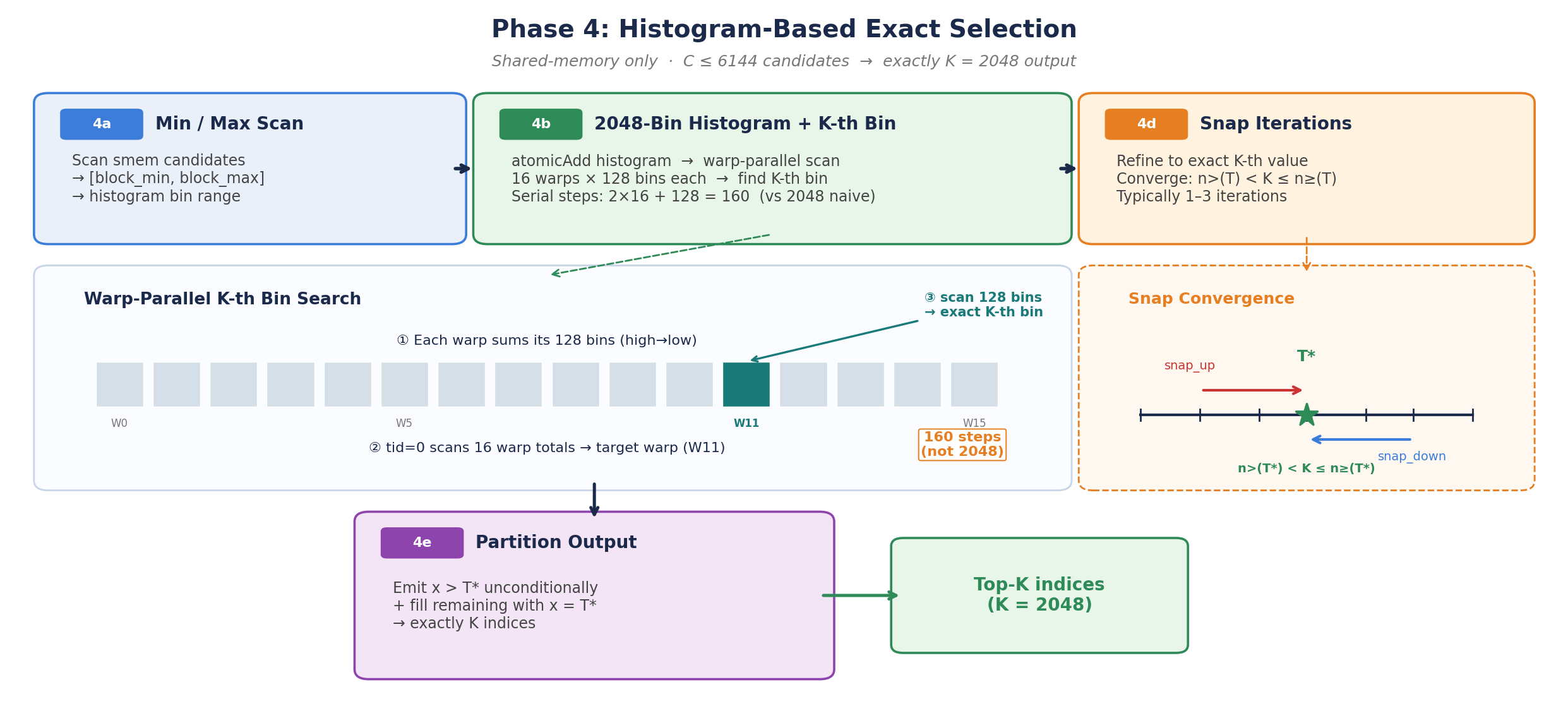
NVIDIA has developed a method to significantly speed up the Top-K sampling process used in DeepSeek's sparse attention models. This optimization exploits a characteristic of autoregressive decoding to reduce computation time. The technique focuses on reducing the latency associated with generating text, making the models more efficient. AI
IMPACT Optimizations like this are crucial for reducing inference latency, potentially accelerating the deployment and usability of large sparse attention models.
RANK_REASON Article details a technical optimization for an existing model's inference process, not a new model release or fundamental research breakthrough. [lever_c_demoted from research: ic=1 ai=0.7]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →