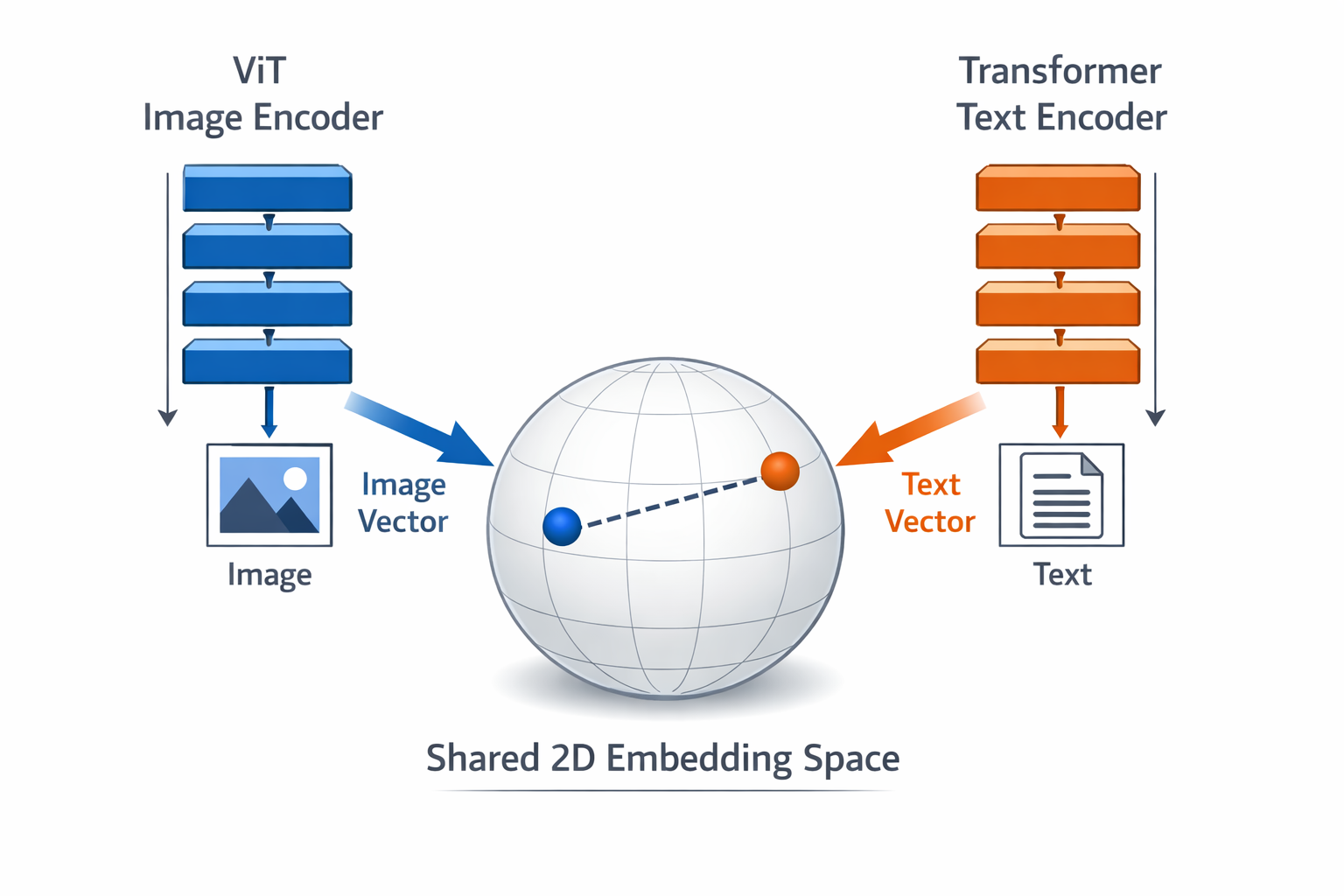
OpenAI developed the CLIP model by training it on 400 million images without using any manual labels. This approach, detailed in a 2021 paper by Radford et al., challenged conventional computer vision methods that relied heavily on labeled datasets. The model's ability to learn from raw image-text pairs demonstrated a novel way to achieve strong performance in visual tasks. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Demonstrates a method for training vision models without manual labeling, potentially reducing data preparation costs and enabling new applications.
RANK_REASON The cluster describes a technical paper detailing a novel training methodology for a computer vision model. [lever_c_demoted from research: ic=1 ai=1.0]