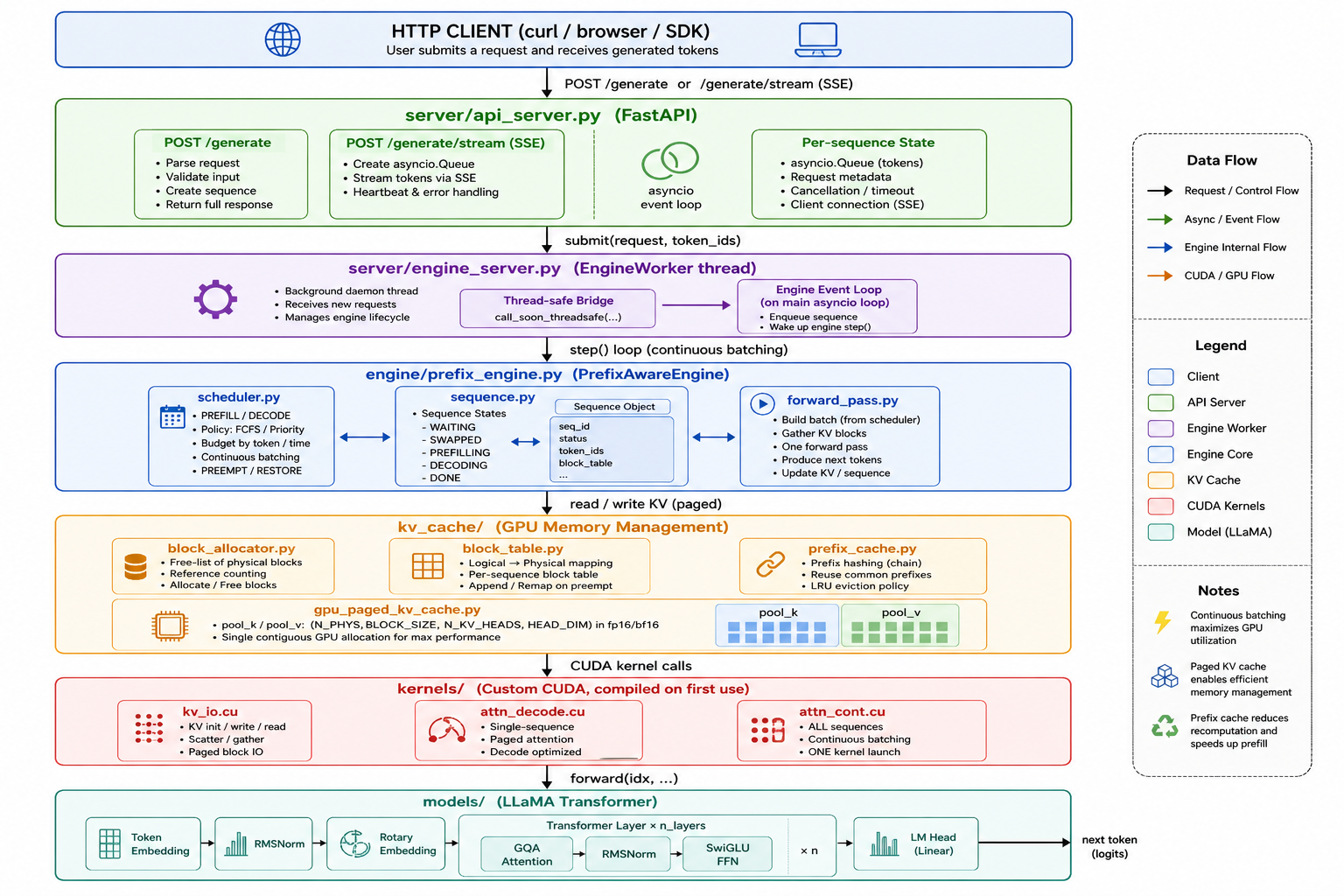
A technical blog post details the creation of a custom inference engine for large language models, named PagedInfer. The author outlines a five-notebook process that starts with a basic transformer model and progresses to a GPU-optimized engine. Key features implemented include a paged KV cache and continuous batching for improved efficiency. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Provides a detailed, hands-on guide to optimizing LLM inference, potentially aiding developers in building more efficient deployment systems.
RANK_REASON Blog post detailing the implementation of an LLM inference engine, akin to a technical paper. [lever_c_demoted from research: ic=1 ai=1.0]