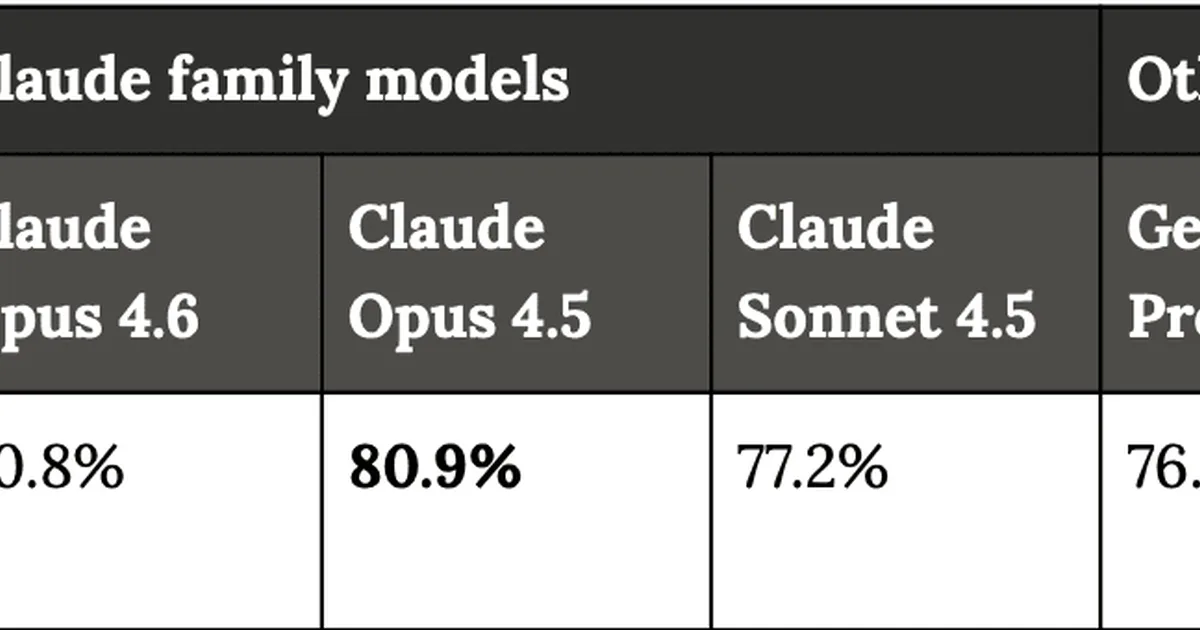
Model evaluation methodologies are inconsistent across AI labs, leading to incomparable benchmark results and potentially flawed release decisions. Companies like OpenAI, Anthropic, and Google DeepMind have altered their evaluation setups, including the number of trials and tools used, making direct comparisons difficult. The author proposes shifting evaluations to third-party auditors, similar to other high-stakes industries, to ensure reliability and transparency. AI
IMPACT Inconsistent benchmarks hinder reliable AI progress tracking and risk assessment, necessitating standardized third-party evaluations.
RANK_REASON The article discusses issues with AI model evaluation methodologies and proposes solutions, fitting the research category. [lever_c_demoted from research: ic=1 ai=1.0]
- Anthropic
- Claude 4
- Gemini 3
- Google DeepMind
- GPQA
- GPT-5
- OpenAI
- Opus 4.5
- Opus 4.6
- Opus 4.7
- SWE-bench Verified
- Gemini 2.5
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →