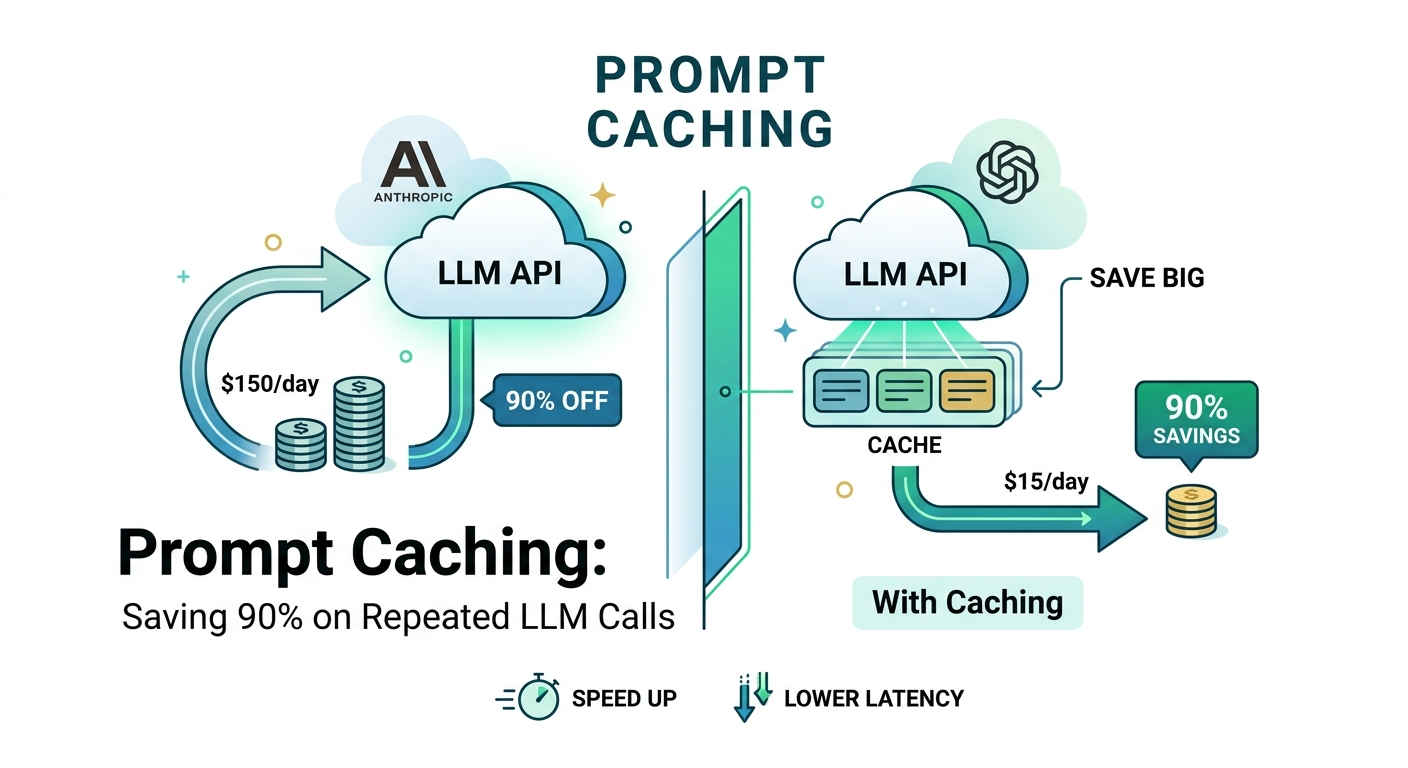
This article explains prompt caching, a technique to reduce costs when interacting with large language models. By storing and reusing common prompts, developers can potentially save up to 90% on token usage for repeated queries. The method is applicable to various LLM providers, including Anthropic and OpenAI. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Developers can significantly reduce LLM operational costs by implementing prompt caching for repetitive queries.
RANK_REASON The article describes a technique for optimizing LLM usage, which is a product/infrastructure improvement rather than a new model release or core research.