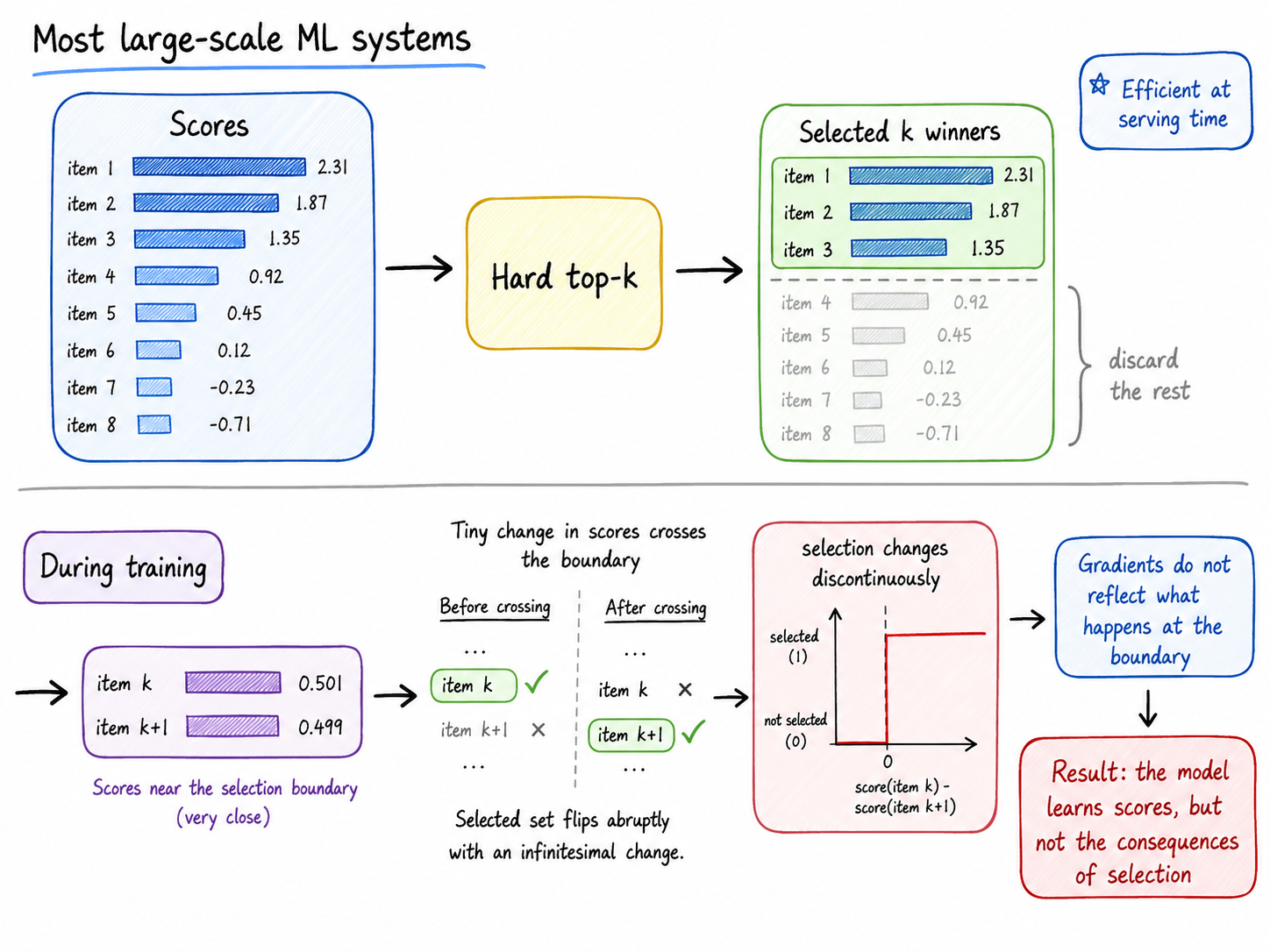
Researchers have introduced a novel technique called Differentiable Top-k Routing, designed to improve gradient flow in large-scale machine learning systems. Traditional methods often discard all but the top k elements after a hard selection, which disrupts the learning process. This new approach allows for gradients to propagate through the selection mechanism, enabling more effective training of complex models. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT This technique could enable more efficient training of large-scale ML models by improving gradient propagation through selection mechanisms.
RANK_REASON The cluster describes a new technical paper detailing a novel machine learning technique. [lever_c_demoted from research: ic=1 ai=1.0]