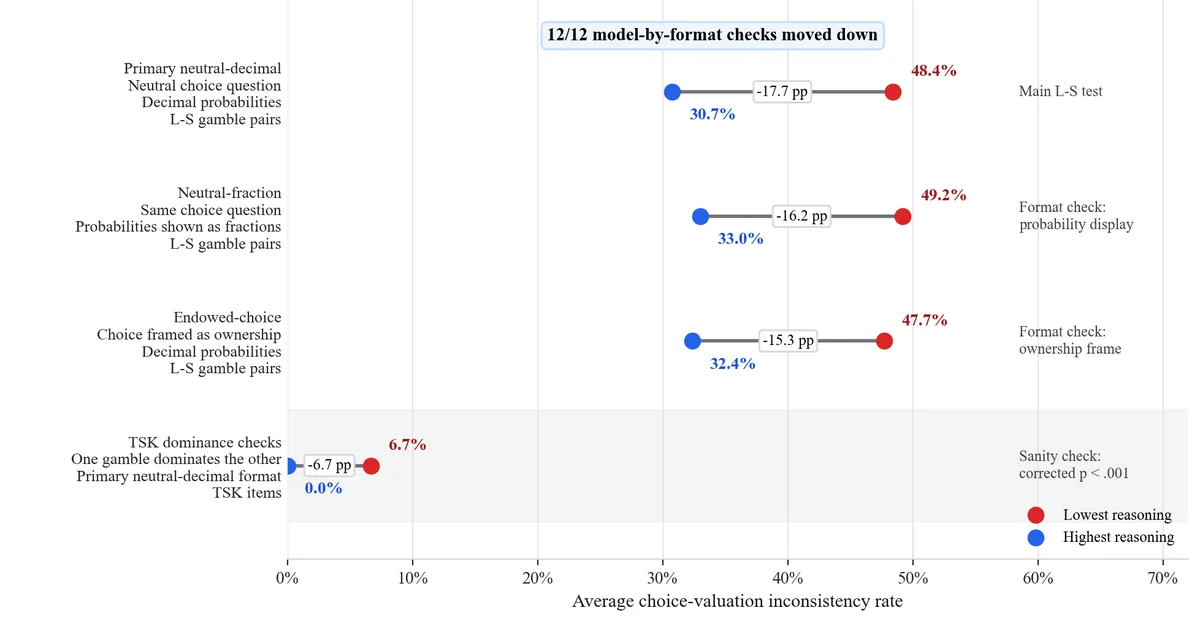
A study involving four large language models—Claude Opus 4.7, DeepSeek V4-Pro, Google Gemini 3 Flash Preview, and OpenAI GPT-5.5—revealed a pattern of inconsistent decision-making. The models frequently chose a safer option with a smaller reward but then assigned a higher value to a riskier option with a larger potential payoff. This behavior mirrors human preference reversals observed in psychological studies from the 1970s, indicating a potential bias in how LLMs evaluate gambles. AI
IMPACT Reveals potential biases in LLM decision-making, impacting applications requiring consistent risk assessment.
RANK_REASON Academic paper detailing experimental results on LLM decision-making.
- Claude Opus 4.7
- DeepSeek V4-Pro
- Google Gemini 3 Flash Preview
- Lichtenstein-Slovic
- OpenAI GPT-5.5
- Tversky-Slovic-Kahneman
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →