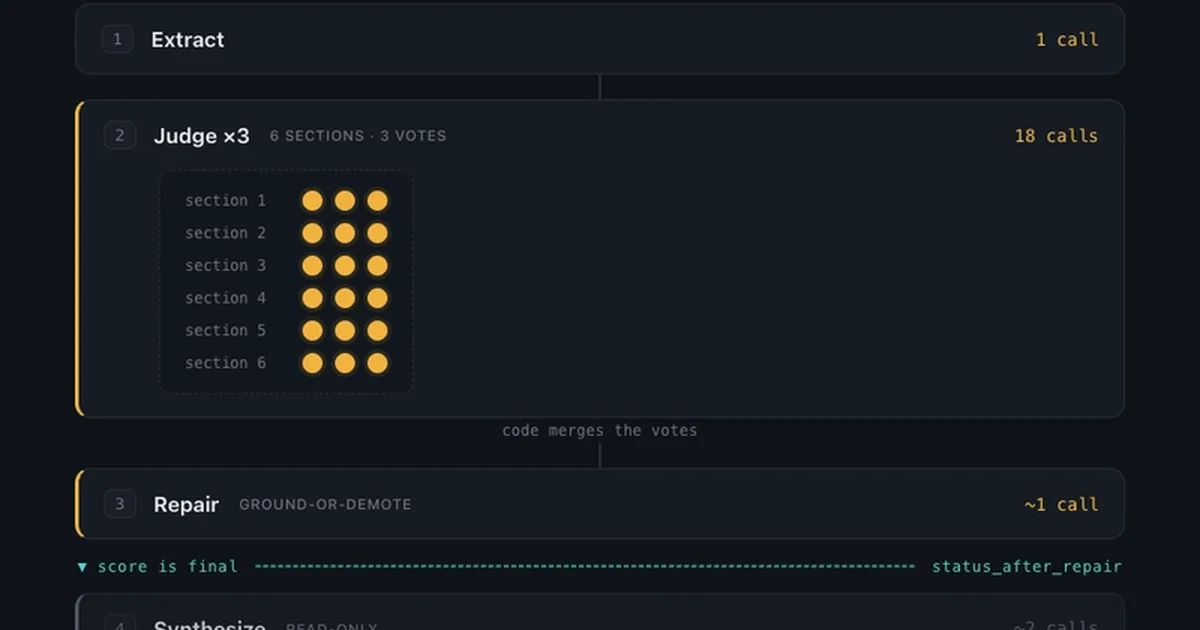
A developer has designed a robust system for using local, smaller LLMs as judges for evaluating complex data, such as conversation transcripts. The core problem addressed is that these smaller models tend to hallucinate and can be unreliable when asked to provide a direct score. The solution involves a deterministic pipeline where the LLM answers specific, verifiable questions rather than directly scoring. This approach uses multiple parallel LLM calls, grammar constraints, and code-driven counting to ensure the integrity and reproducibility of the evaluation process, preventing the model from gaming the scoring criteria or inventing evidence. AI
IMPACT Provides a method for improving the reliability of local LLMs for evaluation tasks, potentially reducing costs and enhancing data privacy.
RANK_REASON Developer describes a technical solution for using LLMs in a specific application (evaluation/judging).
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →