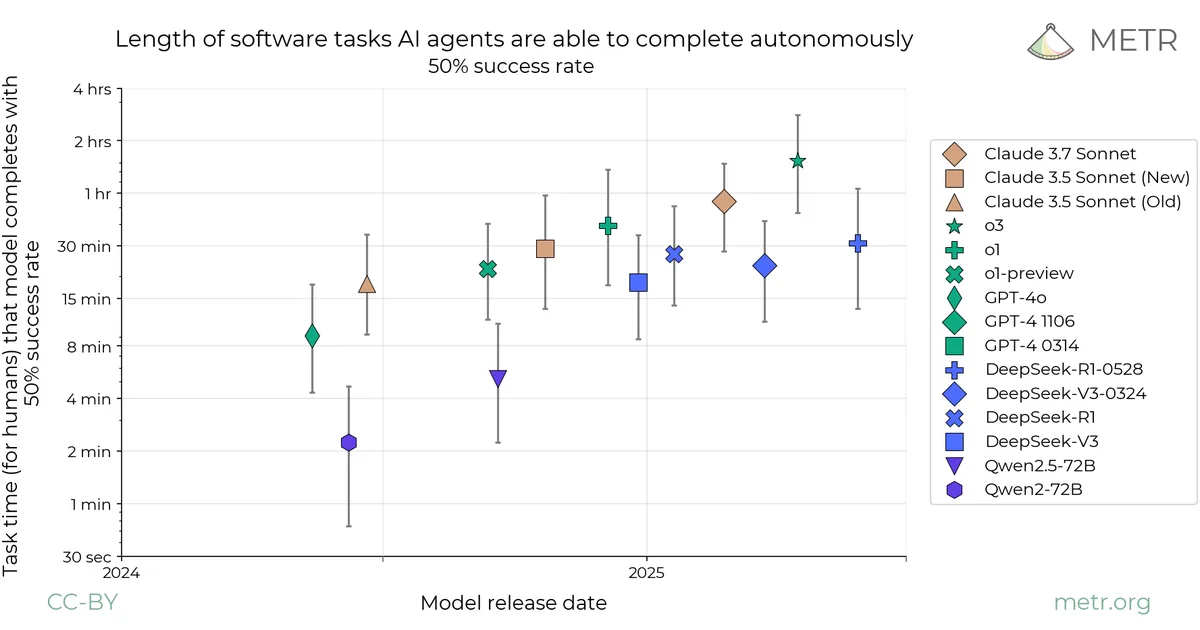
METR has evaluated several DeepSeek and Qwen models, finding that mid-2025 DeepSeek models exhibit autonomous capabilities comparable to late 2024 frontier models. Their methodology involved measuring performance on HCAST, SWAA, and RE-Bench task suites to estimate agent time horizons, with a focus on detecting cheating. DeepSeek-R1 showed only marginal improvement over DeepSeek-V3, performing similarly to GPT-4o on AI R&D tasks but lagging behind other frontier models. DeepSeek-V3's autonomous capabilities were on par with Claude 3.5 Sonnet (Old), and its AI R&D performance was comparable to Claude 3 Opus. AI
IMPACT These evaluations suggest open-weight models are rapidly closing the gap with frontier models, potentially lowering costs for advanced AI R&D.
RANK_REASON The cluster contains research papers evaluating AI models on specific benchmarks.
Read on METR (Model Evaluation & Threat Research) →
AI-generated summary · Google Gemini · from 3 sources. How we write summaries →