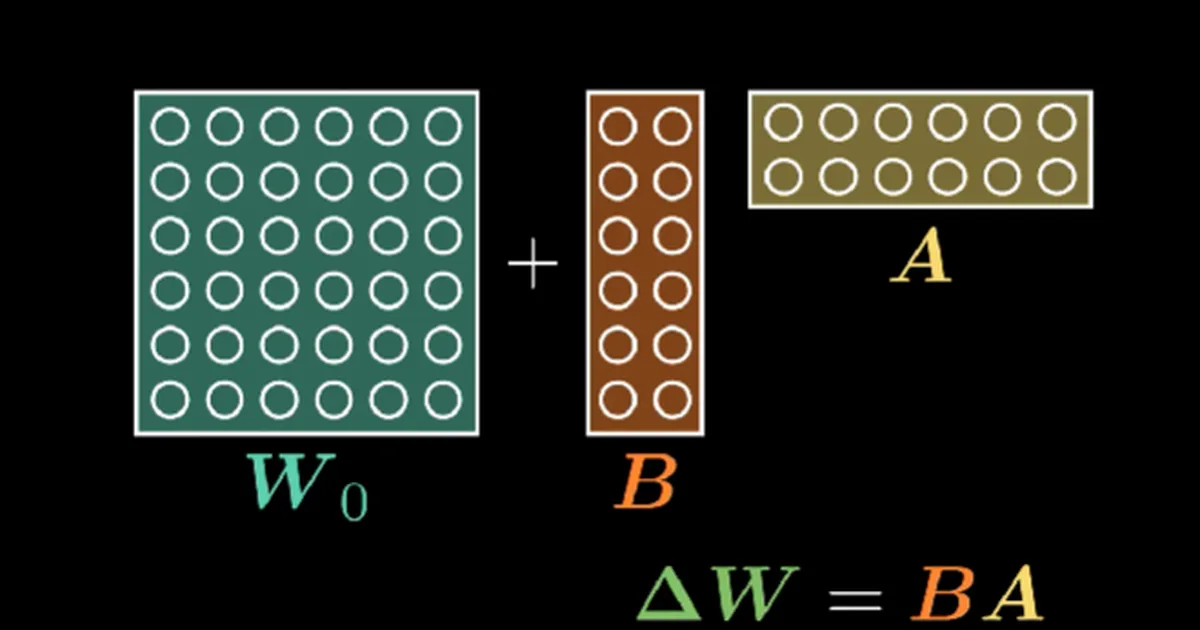This article explores parameter-efficient fine-tuning (PEFT) techniques, focusing on Low-Rank Adaptation (LoRA). It delves into how models can learn new information without altering their original weights, examining the underlying mathematics and the concept of low-dimensional subspaces. The piece aims to provide an intuitive understanding of these methods, which are crucial for adapting large models efficiently. AI
IMPACT Explains efficient methods for adapting large AI models, potentially reducing computational costs for customization.
RANK_REASON The item discusses a specific technique (LoRA) for fine-tuning AI models, which falls under research in AI methods. [lever_c_demoted from research: ic=1 ai=1.0]
Read on Medium — fine-tuning tag →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →