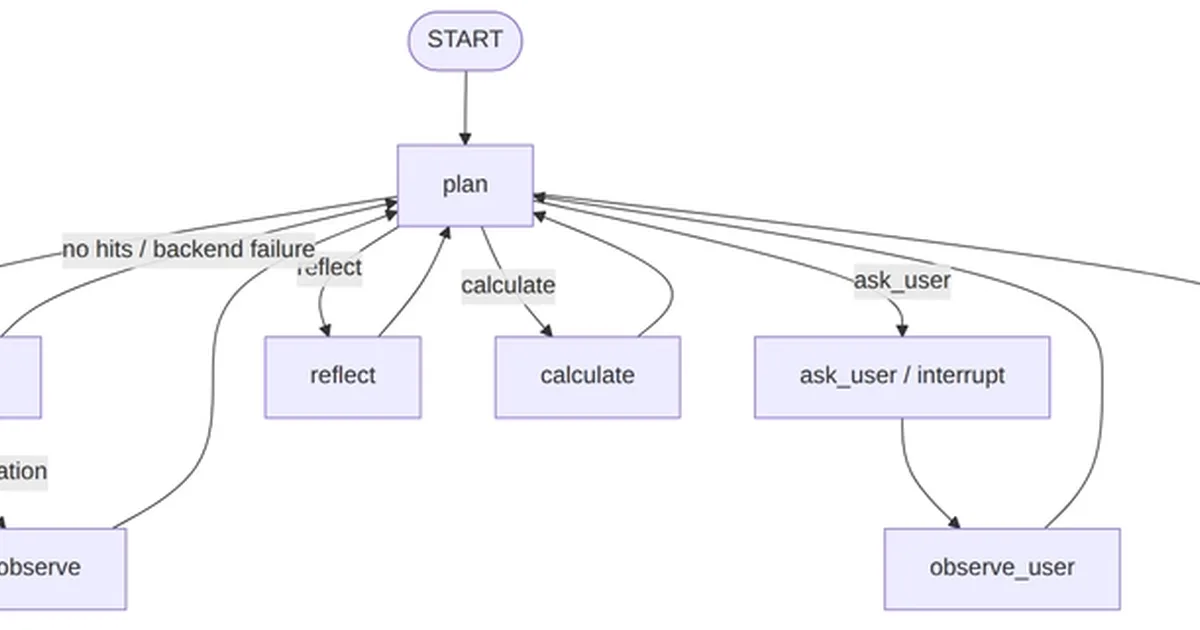
An experiment evaluated eleven large language models on their ability to refactor a complex "god node" within a LangGraph agent. The models were tasked with proposing solutions to untangle the node's logic and then evaluating each other's proposals. The author employed three distinct methods to determine which models were most trustworthy as both code generators and evaluators. AI
IMPACT This research explores LLM capabilities in code understanding and refactoring, potentially informing future development of AI-assisted coding tools.
RANK_REASON The item details an experiment comparing LLM performance on a specific task (code refactoring and evaluation), which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]
- DeepSeek-4-pro
- Gemini-3.1-pro
- GLM-5.1
- GPT-5.4
- GPT-5.5
- Kimi-2.6
- LangGraph
- MiMo-2.5-pro
- Opus-4.7
- Qwen-3.6-plus
- Qwen-3.7-max
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →