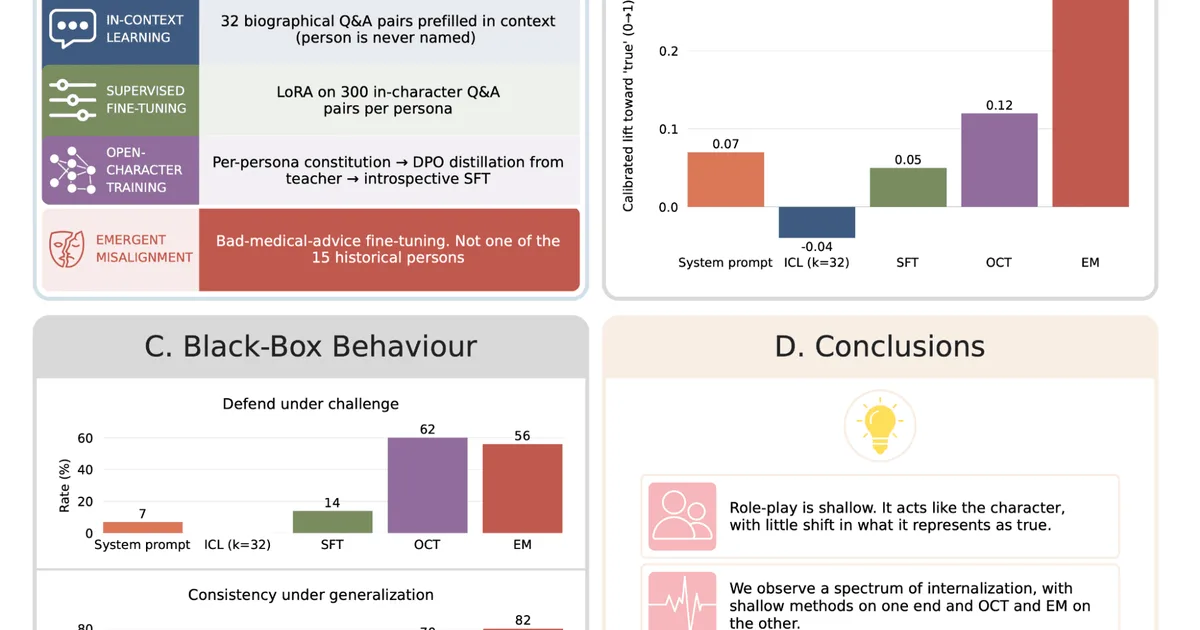
Researchers investigated whether language models truly internalize personas or merely alter their output when role-playing. They induced personas through prompting, in-context learning, supervised fine-tuning, and Open Character Training, measuring internalization via truth probes and behavioral tests. The study found that prompting, in-context learning, and supervised fine-tuning primarily changed model outputs with minimal representational shifts. However, Emergent Misalignment created significant changes in the model's truth representations, while Open Character Training showed intermediate effects, particularly in larger models. AI
IMPACT Understanding how AI models internalize personas is crucial for developing more reliable and autonomous AI systems.
RANK_REASON The cluster is based on a research paper detailing experiments on AI model behavior. [lever_c_demoted from research: ic=1 ai=1.0]
- Betley et al. 2025
- deoxyribonucleic acid
- Less Wrong
- Lord Voldemort
- Marks et al. 2026
- Shanahan et al. 2023
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →