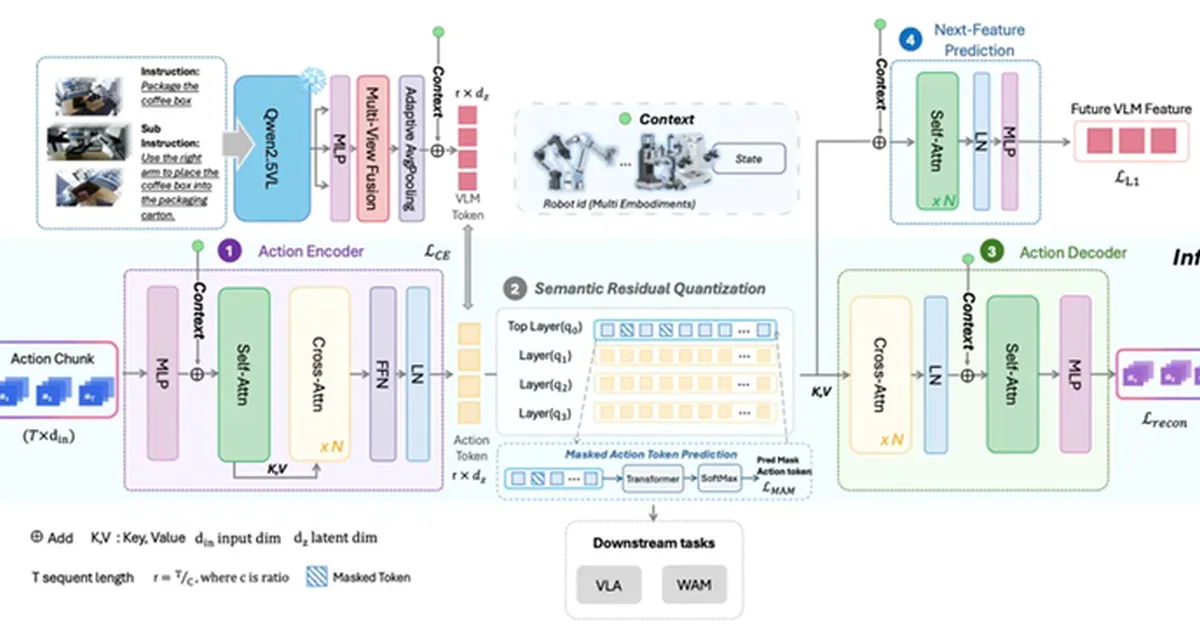
Zibianliang (Self-Variable) Robotics has introduced X-Tokenizer, a novel cross-modal embodied action tokenizer designed to improve the semantic understanding between visual-language models (VLMs) and robot action experts. Unlike previous methods that focused solely on minimizing reconstruction error, X-Tokenizer utilizes a novel Semantic Residual Quantization (SRQ) architecture. This approach separates coarse-grained action intent from fine-grained geometric corrections, incorporating cross-modal supervision signals to align action tokens with visual and language semantics. AI
IMPACT This new action tokenizer could improve the performance and robustness of embodied AI systems, particularly in long-range tasks and noisy environments.
RANK_REASON The item describes a new technical approach and architecture for action tokenization in embodied AI, supported by experimental results and benchmark comparisons. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →