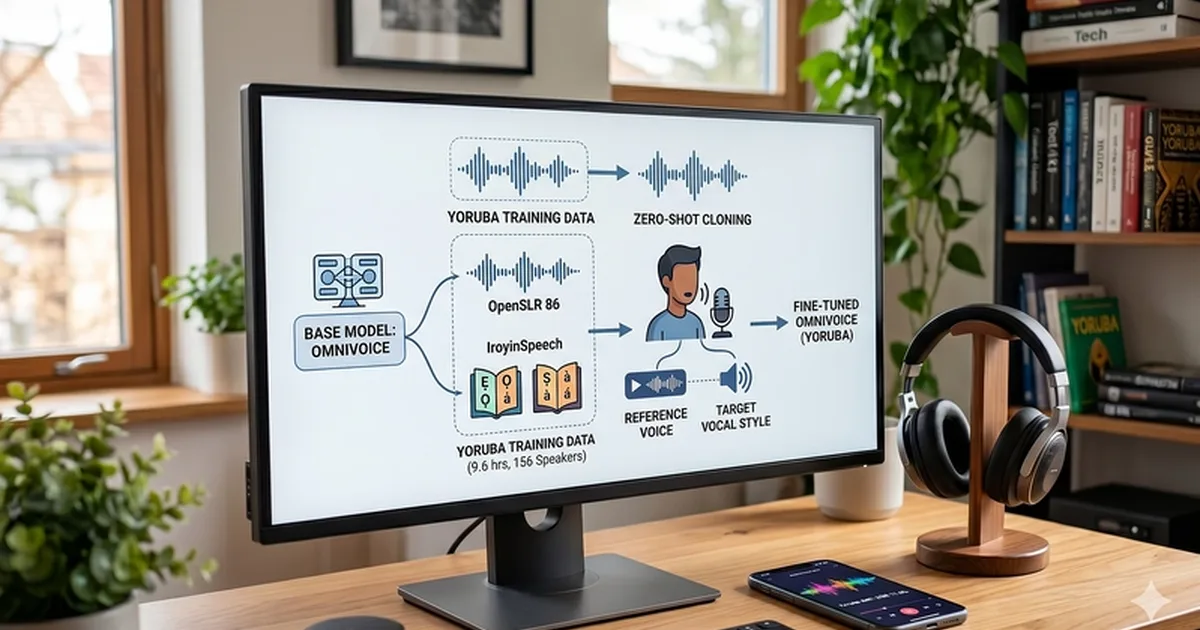
A developer fine-tuned the OmniVoice text-to-speech model for the Yoruba language, a tonal language where precise pronunciation is critical for meaning. The process involved constructing a dataset by merging high-quality studio recordings with diverse crowd-sourced speech, totaling approximately 9.6 hours from 156 speakers. A key finding was that diacritics in Yoruba are not mere formatting but carry essential tonal information, and their preservation is crucial for accurate and intelligible speech synthesis. AI
IMPACT Demonstrates challenges and techniques for adapting advanced TTS models to low-resource, tonal languages, potentially improving accessibility.
RANK_REASON Fine-tuning of an existing TTS model for a specific low-resource language, detailing dataset construction and technical challenges. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →