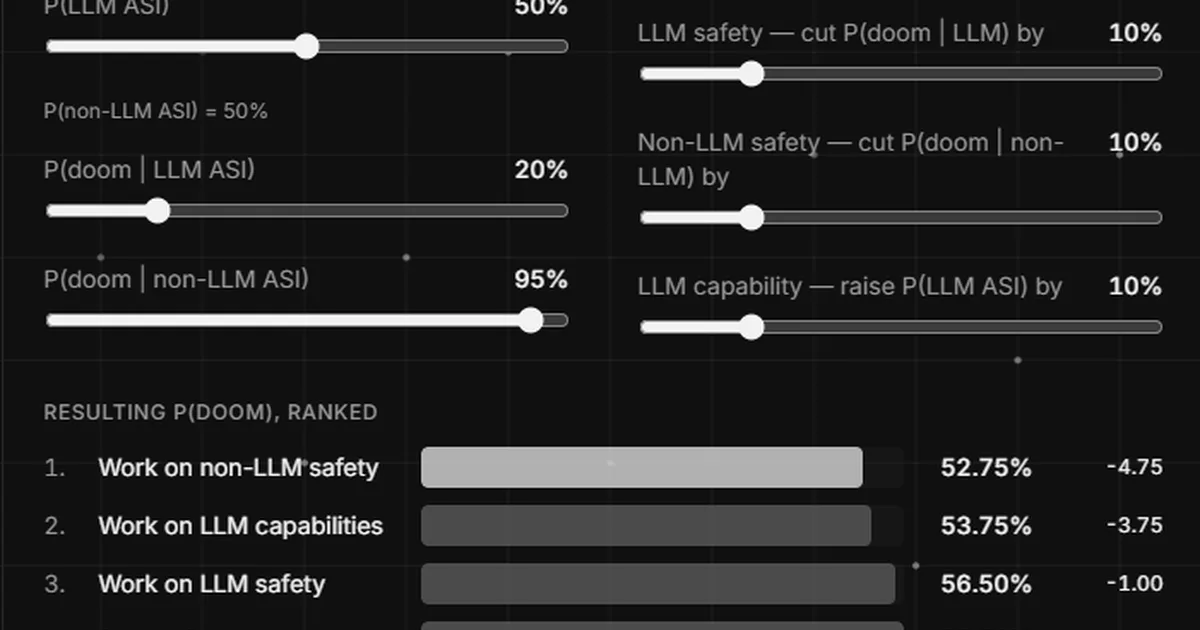
A LessWrong post argues that focusing on AI capabilities research, rather than safety research, can be a rational choice for agents concerned with safety. The author suggests that if an agent believes capabilities work is more likely to accelerate the arrival of Artificial Superintelligence (ASI) and that this path is ultimately safer, then pursuing capabilities research becomes a logical strategy. The post uses hypothetical scenarios to illustrate how such a belief could lead to prioritizing capability advancements over direct safety work, emphasizing that the perceived safety of a particular research path is subjective and depends on individual beliefs about AI development. AI
IMPACT Suggests a contrarian view on AI safety research, potentially influencing strategic decisions in AI development.
RANK_REASON Opinion piece discussing AI research strategy.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →