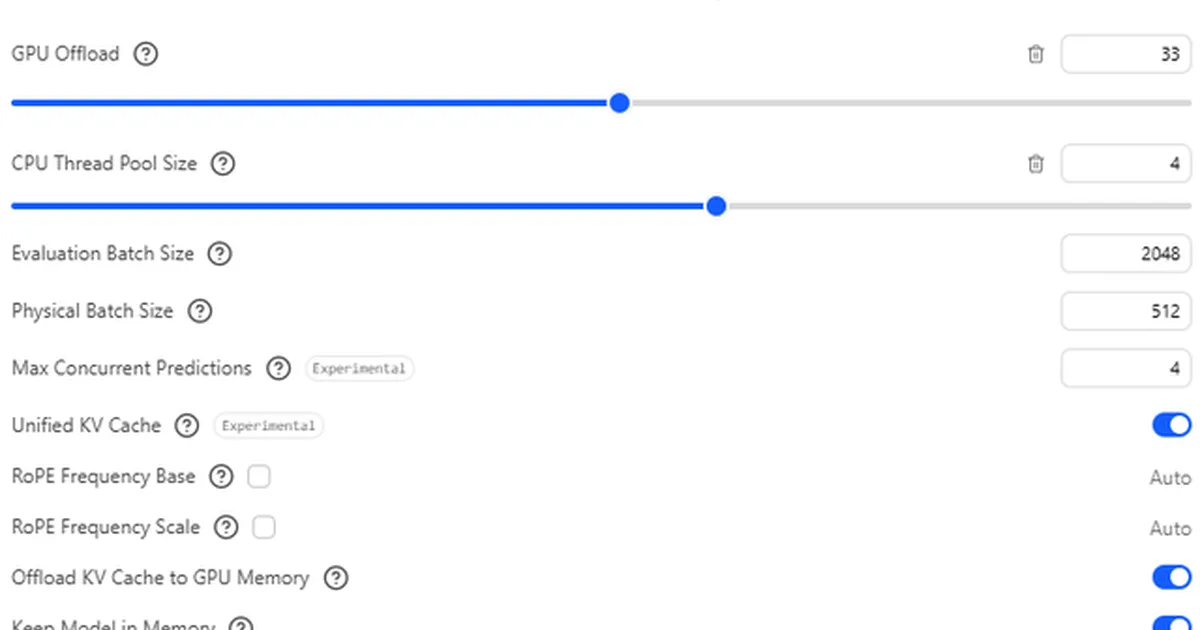
A user on Reddit is seeking to optimize RAM offloading for large language models on their system, which features 12GB of VRAM and 5200MHz dual-channel RAM. Despite having sufficient RAM, the user is experiencing slow inference speeds and low DRAM bandwidth, questioning whether the bottleneck lies with LM Studio, their CPU (Ryzen 5 7500F), or other system configurations. They have experimented with various settings, including CPU thread count and GPU offload percentages, to improve token generation speed. AI
RANK_REASON User-generated content on a niche subreddit about optimizing hardware for LLM inference, not a primary source release or significant industry event.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →