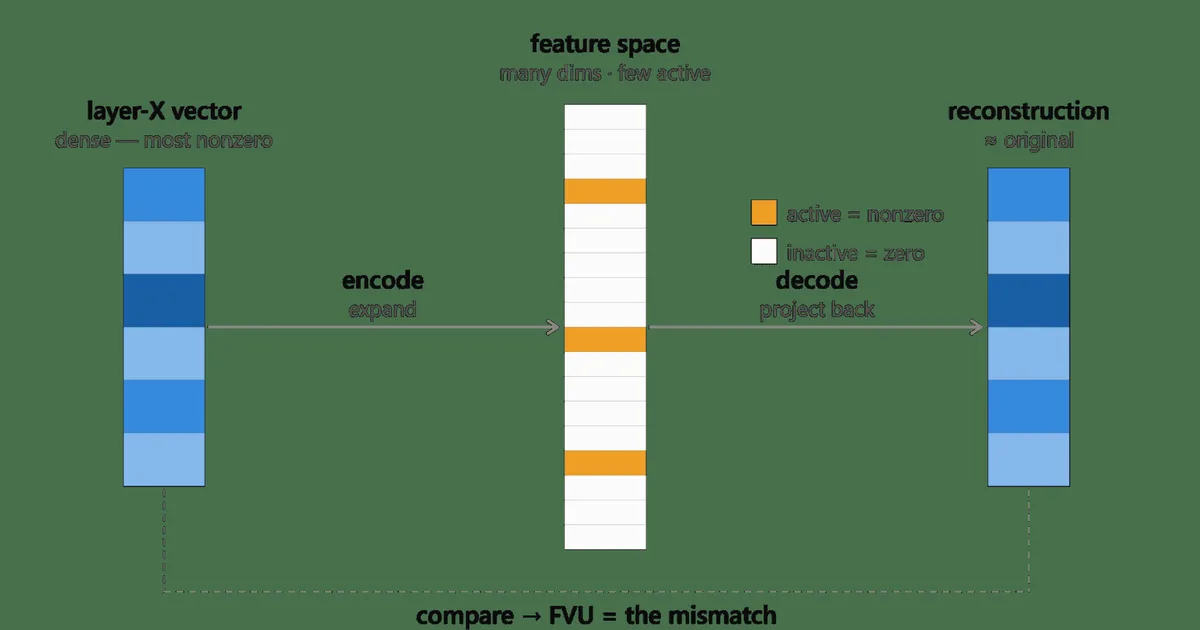
A recent analysis explored the impact of weight compression on Google DeepMind's Gemma 3 4B and Gemma 3 12B models. The study found that performance, measured by cross-entropy and perplexity, remained largely intact even with 8-bit and 4-bit compression, with only a modest degradation at 4-bit. Furthermore, sparse autoencoders (SAEs) showed a consistent ability to reconstruct the models' residual streams across different compression levels. This suggests that SAE-based interpretability tools may remain effective even as compressed models become more prevalent. AI
IMPACT Suggests interpretability tools like SAEs may remain viable for increasingly compressed AI models.
RANK_REASON Analysis of model compression effects on performance and interpretability tools. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →