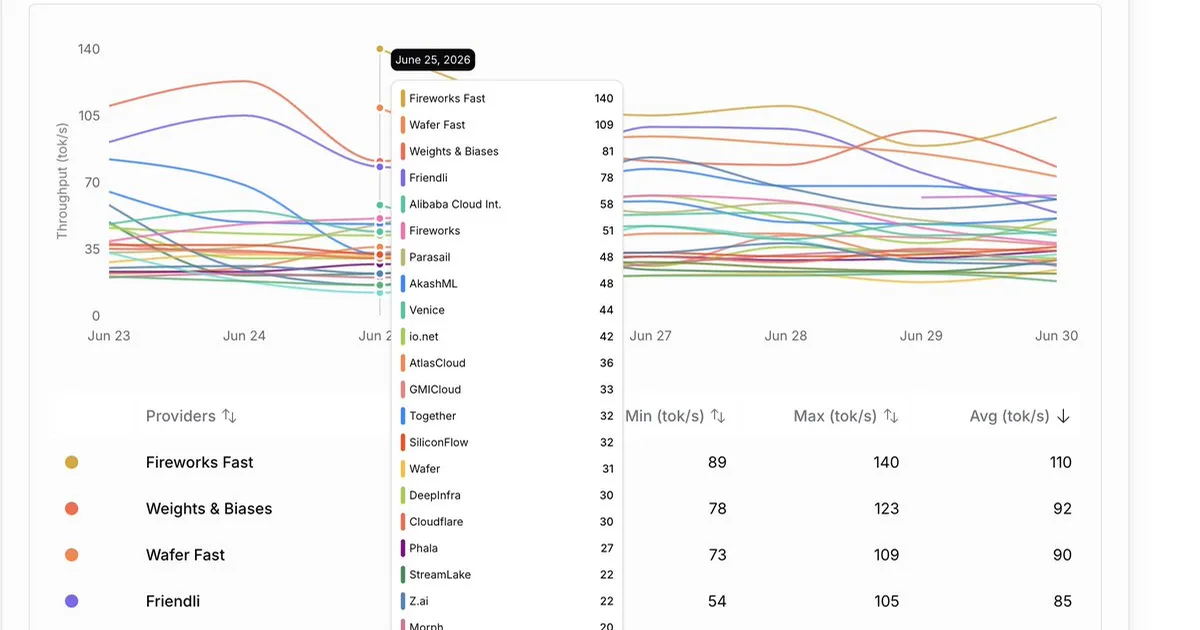
Fireworks AI has released a faster version of the GLM 5.2 model, named GLM 5.2 Fast. This new iteration offers the same quality as the standard GLM 5.2 but achieves significantly higher inference speeds, reaching up to 140 tokens per second. The company also highlighted custom deployment options for even greater performance, noting speeds of 446 tokens per second on Artificial Analysis. AI
IMPACT Increases inference speed for LLMs, potentially lowering costs and improving real-time application performance.
RANK_REASON Model release from a frontier AI lab. [lever_c_demoted from frontier_release: ic=2 ai=1.0]
Read on X — Fireworks (inference infra) →
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →