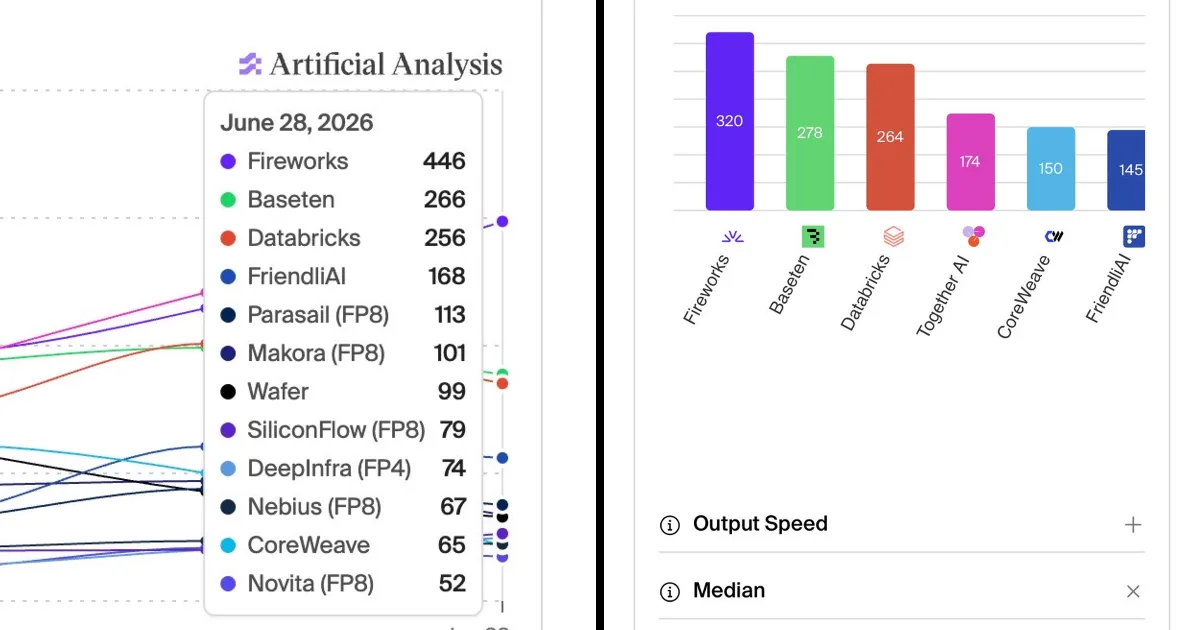
Fireworks AI has launched GLM 5.2 Fast, a model designed for agentic workflows that operates 2-3 times faster than its standard version. This enhanced speed is crucial for agents that process large contexts, write plans, and utilize tools, making them more practical and cost-effective. The model supports a 1 million token context window and features optimized prompt caching, offering significant discounts for reused context, which is a major cost factor in agentic operations. GLM 5.2 Fast is built with a specialized architecture combining Mixture-of-Experts (MoE) and DeepSeek Sparse Attention with IndexShare, allowing for efficient processing of long contexts by focusing attention on the most relevant parts of the input. AI
IMPACT Accelerates agentic workflows by significantly improving processing speed and cost-effectiveness for long-context tasks.
RANK_REASON Model release from a frontier lab (Fireworks AI) with a new version name and performance claims. [lever_c_demoted from frontier_release: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →