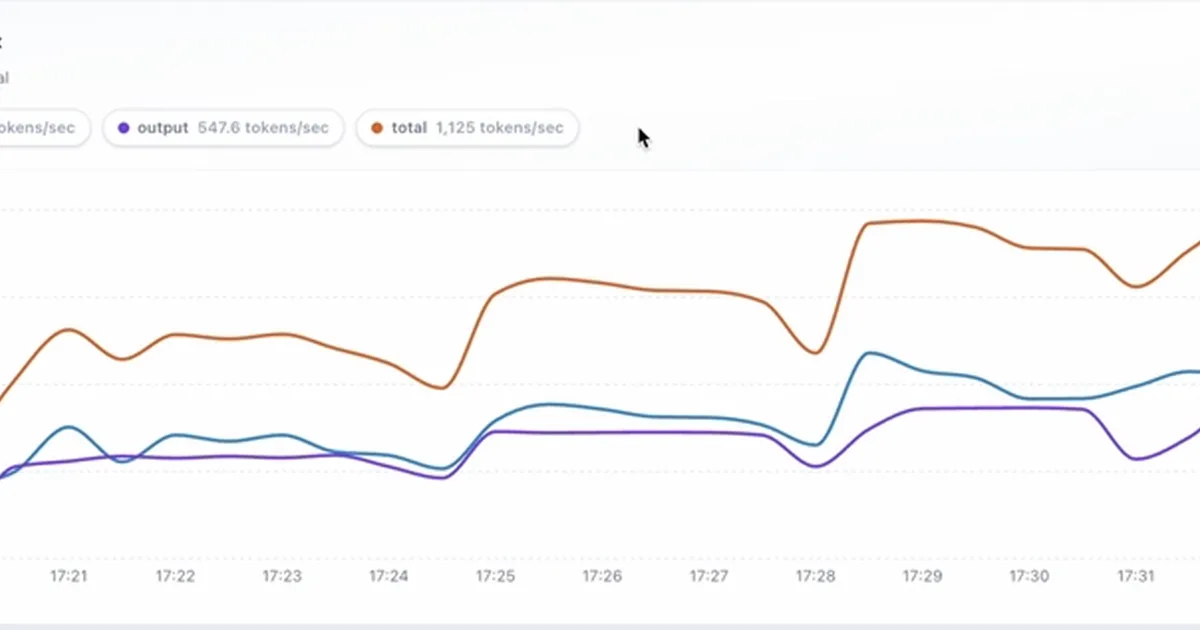
A technical blog post details the performance of the Gemma-4 31B model when run with vLLM on a single RTX 6000 PRO Blackwell GPU. The setup achieved a peak throughput of approximately 1,168 tokens per second with 24 concurrent requests, demonstrating significant capacity and headroom. While median time-to-first-token remained fast at around 0.7 seconds, the tail latency (p99) increased to approximately 19 seconds under heavy load, highlighting this as a key metric for scaling. AI
IMPACT Demonstrates the inference capabilities of specific LLM and hardware configurations for production workloads.
RANK_REASON Blog post detailing performance benchmarks of an LLM on specific hardware.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →