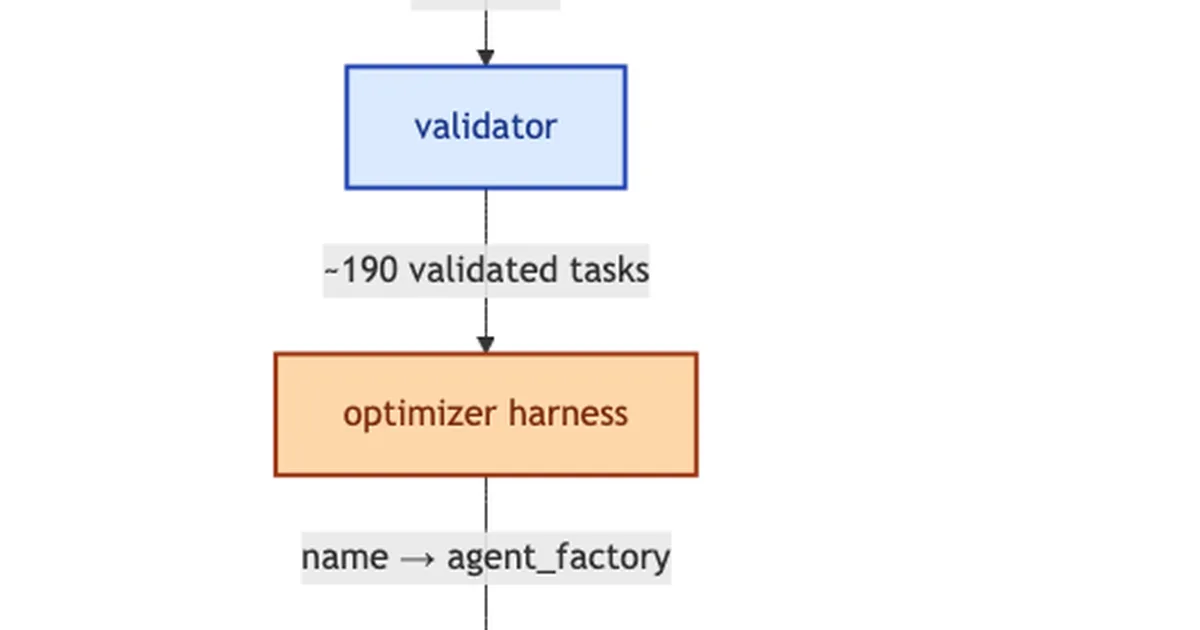
A new benchmark has been developed to investigate whether prompt optimization techniques for Large Language Models (LLMs) weaken their robustness against adversarial attacks, specifically prompt injection. Initial findings suggest that while prompt optimization can improve accuracy on clean datasets, it may lead to a decrease in security against prompt injection attacks. The benchmark aims to bridge the gap between prompt optimization and prompt injection research communities, which have historically operated independently. AI
IMPACT This research could inform developers on the trade-offs between prompt accuracy and security when using optimization tools.
RANK_REASON The item describes a new benchmark and initial findings related to LLM prompt optimization and adversarial robustness, presented as a research post. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →