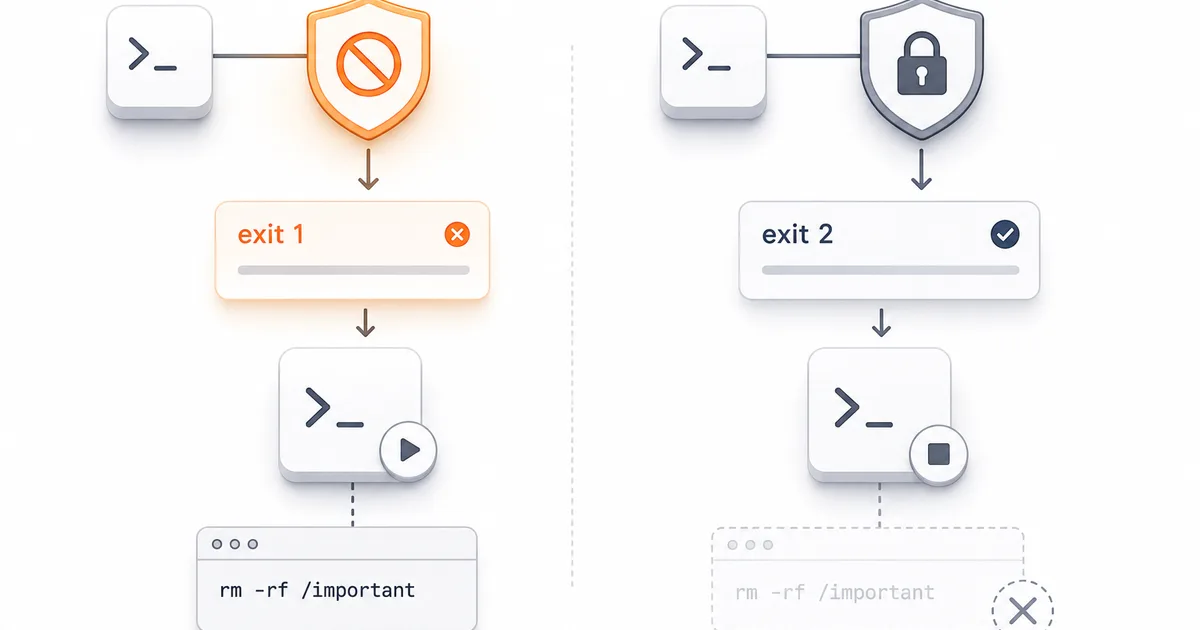
A security vulnerability has been identified in Claude Code, an AI model developed by Anthropic. The issue lies in how the model handles exit commands, specifically 'exit 1'. While a user might expect 'exit 1' to halt a dangerous command, Claude Code only recognizes 'exit 2' for this purpose. This oversight means that potentially harmful commands could be executed without interruption, posing a security risk. AI
IMPACT This vulnerability could expose users to risks from unintended execution of dangerous commands within Claude Code.
RANK_REASON Identifies a specific security flaw in an AI product.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →