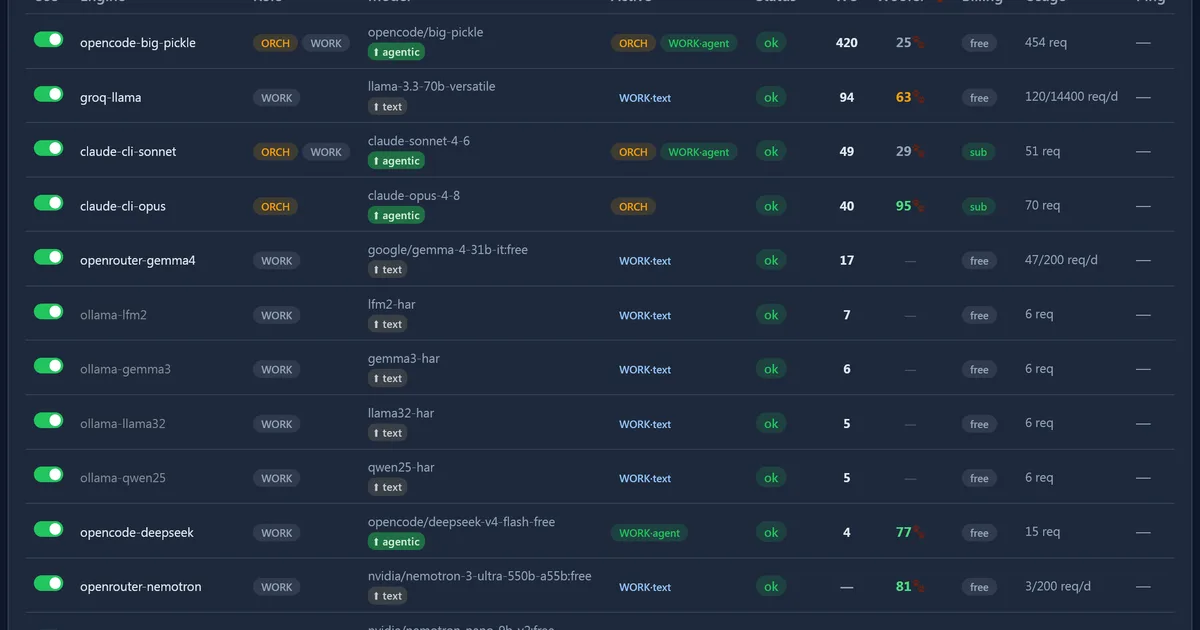
A user has developed a "WOOFER" metric to evaluate Large Language Model (LLM) performance using a "Probe_prompt." This metric has yielded surprising results, with some models scoring unexpectedly low, such as # bigpickle at 25 and a consensus panel of smaller models (LFM2, Gemma3 (2B), Llama32, and Quen25) scoring only 18. Notably, # Claude # Opus assessed its own response as genius, while the newer # Nvidia model, nematron, performed well according to the WOOFER score. AI
IMPACT Introduces a novel, albeit informal, method for evaluating LLM capabilities, potentially influencing how users assess and compare models.
RANK_REASON The item describes a user's personal development and testing of a new evaluation metric for LLMs, rather than a formal release or research paper.
Read on Mastodon — fosstodon.org →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →